October 21 post-incident analysis
10월 21일 장애 사후 분석
Last week, GitHub experienced an incident that resulted in degraded service for 24 hours and 11 minutes. While portions of our platform were not affected by this incident, multiple internal systems were affected which resulted in our displaying of information that was out of date and inconsistent. Ultimately, no user data was lost; however manual reconciliation for a few seconds of database writes is still in progress. For the majority of the incident, GitHub was also unable to serve webhook events or build and publish GitHub Pages sites.
지난 주, 깃헙(GitHub)에 문제가 발생해 24시간 11분 동안 제한된 서비스만 제공할 수 있었습니다. 일부 플랫폼은 영향 밖에 있었지만, 많은 내부 시스템이 영향을 받아 일관되지 않고 부정확한 정보를 표시하는 문제가 있었습니다. 최종적으로 어떠한 사용자 데이터도 잃어버리진 않았습니다. 하지만 데이터베이스 쓰기 작업에 대한 수 초간의 수동 조작은 아직 진행중입니다. 대부분의 문제는 웹훅 이벤트를 제공하지 못하거나 깃헙 페이지 사이트를 만들고 퍼블리싱하지 못하는 것이었습니다.
All of us at GitHub would like to sincerely apologize for the impact this caused to each and every one of you. We’re aware of the trust you place in GitHub and take pride in building resilient systems that enable our platform to remain highly available. With this incident, we failed you, and we are deeply sorry. While we cannot undo the problems that were created by GitHub’s platform being unusable for an extended period of time, we can explain the events that led to this incident, the lessons we’ve learned, and the steps we’re taking as a company to better ensure this doesn’t happen again.
깃헙 구성원 모두는 이 사건이 일어난 것에 대해 여러분 한 분 한 분에게 진심으로 사과의 말씀을 드립니다. 깃헙에 대한 여러분의 신뢰를 잘 이해하고 고가용성 플랫폼을 구축하는 저희의 탄력적 시스템 구축 기술에 자부심도 가지고 있습니다. 이번 사건으로 여러분에게 실망을 드려 대단히 죄송합니다. 깃헙 플랫폼을 사용할 수 없었던 긴 시간동안 이로 인해 발생한 문제들을 저희가 되돌릴 수는 없겠지만, 문제의 원인과 이번 사고를 통해 저희가 배운 것들, 그리고 이런 일이 다시는 일어나지 않도록 회사 입장에서 취할 수 있는 조치에 대해 설명드리고 싶습니다.
Background
사건 배경
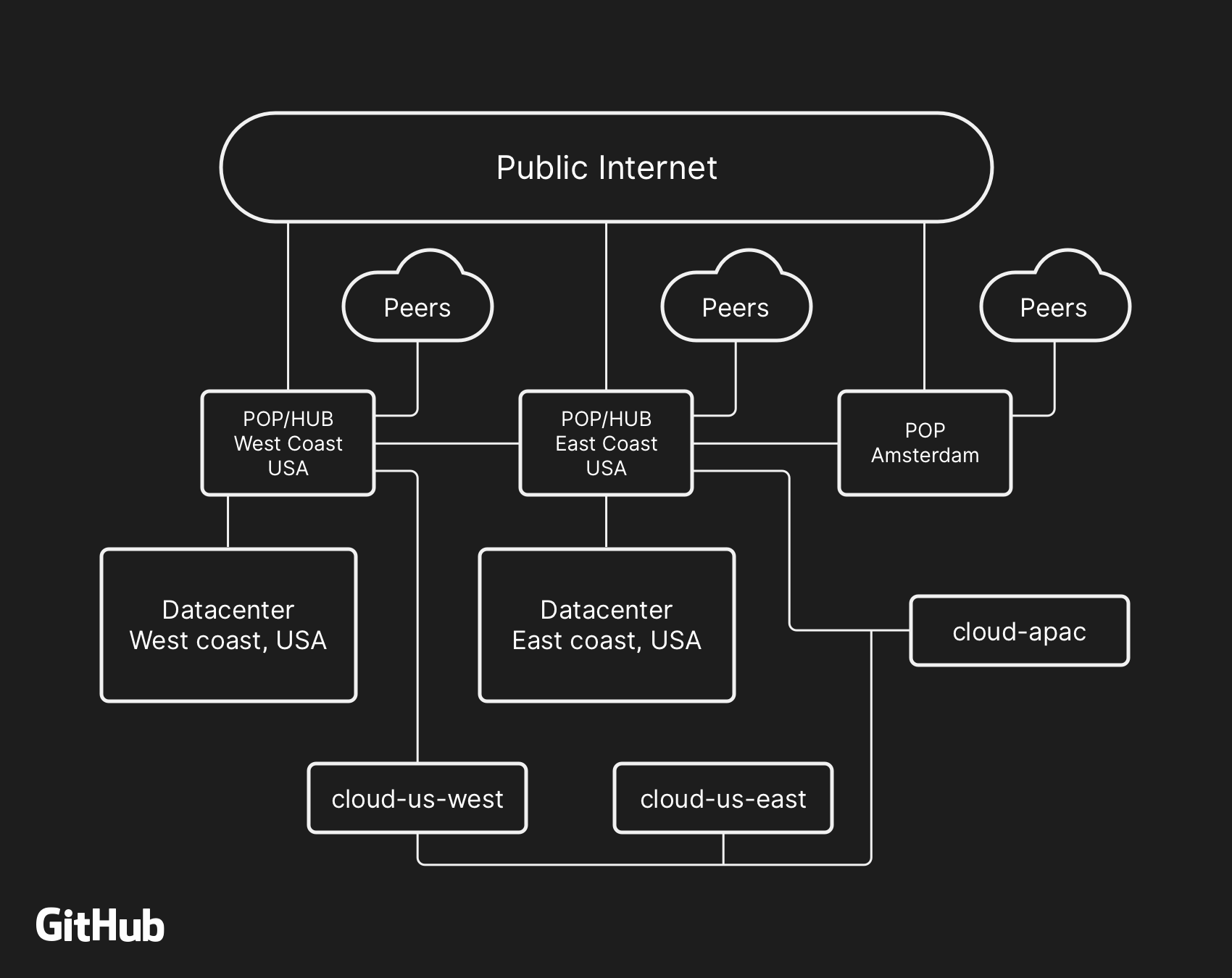
The majority of user-facing GitHub services are run within our own data center facilities. The data center topology is designed to provide a robust and expandable edge network that operates in front of several regional data centers that power our compute and storage workloads. Despite the layers of redundancy built into the physical and logical components in this design, it is still possible that sites will be unable to communicate with each other for some amount of time.
사용자에게 노출되는 깃헙 서비스의 대부분은 저희의 자체 데이터 센터에서 동작하고 있습니다. 데이터 센터의 구성은 연산과 저장을 수행하는 여러 지역의 데이터 센터의 앞단에서 견고하고 유연한 엣지 네트워크를 제공하도록 설계되어 있습니다. 이렇게 설계된 물리적이며 논리적인 컴포넌트 위에 여러 층으로 구성된 견고함에도 불구하고, 여전히 일정 시간 동안 사이트가 서로 통신할 수 없을 수도 있습니다.
At 22:52 UTC on October 21, routine maintenance work to replace failing 100G optical equipment resulted in the loss of connectivity between our US East Coast network hub and our primary US East Coast data center. Connectivity between these locations was restored in 43 seconds, but this brief outage triggered a chain of events that led to 24 hours and 11 minutes of service degradation.
10월 21일 22:52 UTC에 망가진 100G 광통신 장비를 교체하는 정기 보수 작업으로 인해 미 동부 해안 네트워크 허브와 주 데이터 센터인 미 동부 데이터 센터간의 연결이 끊겼습니다. 양측의 연결은 43초만에 복구되었습니다만, 이 짧은 끊김으로 인해 24시간 11분간의 서비스 장애가 이어졌습니다.
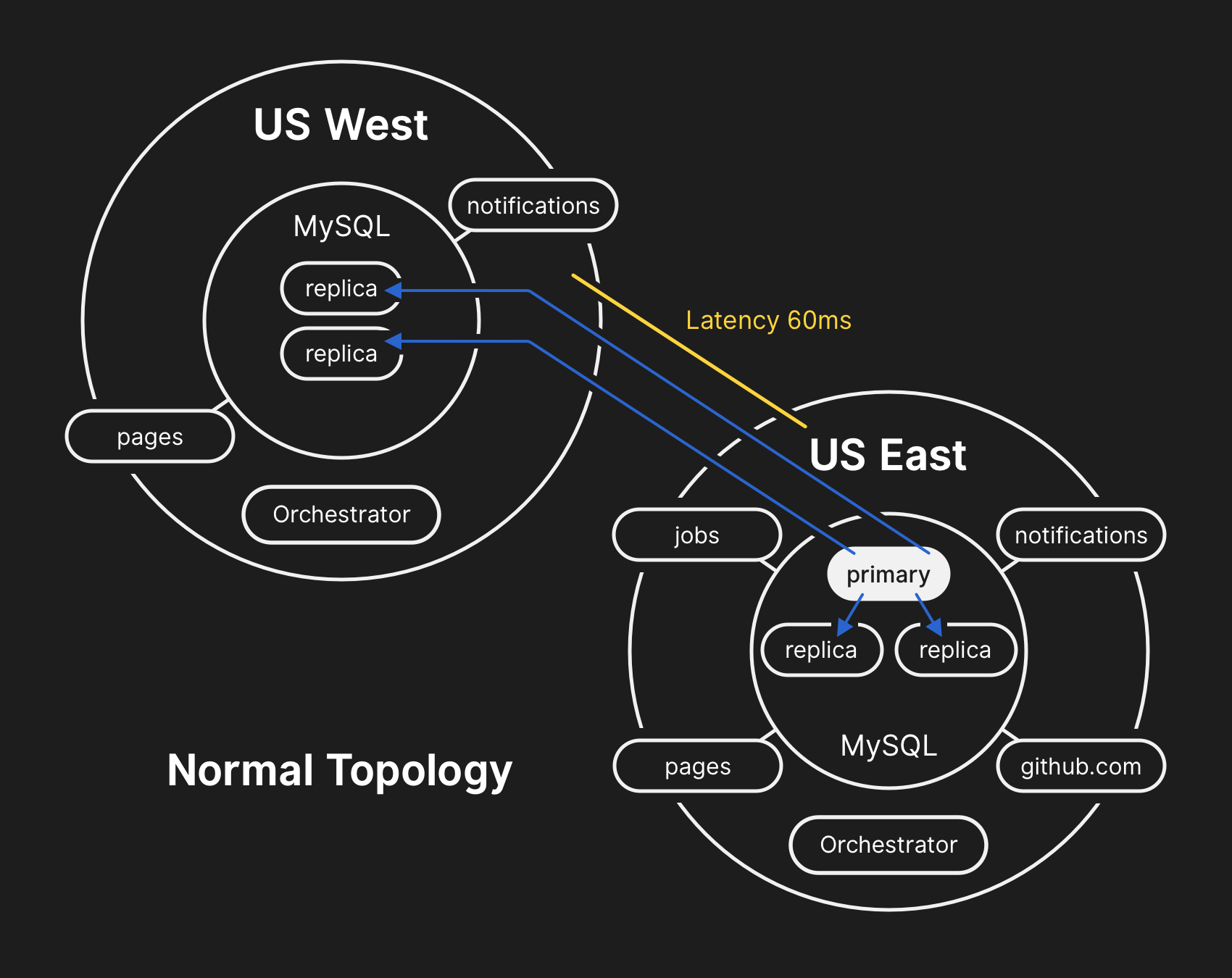
In the past, we’ve discussed how we use MySQL to store GitHub metadata as well as our approach to MySQL High Availability. GitHub operates multiple MySQL clusters varying in size from hundreds of gigabytes to nearly five terabytes, each with up to dozens of read replicas per cluster to store non-Git metadata, so our applications can provide pull requests and issues, manage authentication, coordinate background processing, and serve additional functionality beyond raw Git object storage. Different data across different parts of the application is stored on various clusters through functional sharding.
예전에 저희가 어떻게 MySQL으로 깃헙 메타데이터 저장하는지와 고가용성 MySQL 운영에 대해 논한 적이 있습니다. 깃헙은 수백 기가바이트에서 5 테라바이트에 이르는 다양한 크기의 여러 MySQL 클러스터를 여러 개의 읽기 복제본과 함께 운영하여 깃과 무관한 메타데이터를 저장하고 있습니다. 깃 오브젝트 저장소 외에 풀 리퀘스트와 이슈, 인증 관리, 백그라운드 작업 조율 외 다양한 기능들이 이에 해당합니다. 응용 프로그램의 여러 부분의 서로 다른 데이터들은 기능별 샤딩을 통해 나뉘어 여러 클러스터에 저장됩니다.
To improve performance at scale, our applications will direct writes to the relevant primary for each cluster, but delegate read requests to a subset of replica servers in the vast majority of cases. We use Orchestrator to manage our MySQL cluster topologies and handle automated failover. Orchestrator considers a number of variables during this process and is built on top of Raft for consensus. It’s possible for Orchestrator to implement topologies that applications are unable to support, therefore care must be taken to align Orchestrator’s configuration with application-level expectations.
대규모 서비스에서의 성능 향상을 위해 응용 프로그램은 클러스터내 연관된 주 저장소(primary)에 직접 쓰지만, 대부분의 읽기 요청은 읽기 복제본에 위임하는 편입니다. MySQL 클러스터 구성 관리와 자동 복구를 위해 Orchestrator를 쓰고 있습니다. Orchestrator는 이 과정에서 여러 변수를 고려하여 동작하며, 합의를 위해 Raft를 기반으로 만들어졌습니다. Orchestrator는 응용 프로그램이 지원하지 못하는 수준의 구성이 가능하므로 Orchestrator의 설정을 응용 프로그램의 수준에 맞춰 운영하기 위해서는 주의가 필요합니다.
Incident timeline
사건 타임라인
2018 October 21 22:52 UTC
2018년 10월 21일 22:52 UTC
During the network partition described above, Orchestrator, which had been active in our primary data center, began a process of leadership deselection, according to Raft consensus. The US West Coast data center and US East Coast public cloud Orchestrator nodes were able to establish a quorum and start failing over clusters to direct writes to the US West Coast data center. Orchestrator proceeded to organize the US West Coast database cluster topologies. When connectivity was restored, our application tier immediately began directing write traffic to the new primaries in the West Coast site.
위에서 설명한 것과 같이 네트워크가 나뉜동안, 주 데이터센터에서 동작하던 Orchestrator는 Raft의 합의 원칙에 따라 리더쉽 선택 취소 프로세스를 시작했습니다. 서부 해안 데이터센터와 동부 해안 공용 클라우드의 Orchestrator 노드들은 (합의에 필요한) 정족수를 채우고 서부 해안 데이터센터에 직접 데이터를 쓰도록 클러스터를 복구할 수 있었습니다. Orchestrator는 서부 해안 데이터베이스 클러스터 구성을 조직하기 시작했고, 연결이 복원되자마자 응용 프로그램들은 일제히 새롭게 선출된 서부 해안 쪽으로 데이터를 쓰기 시작했습니다.
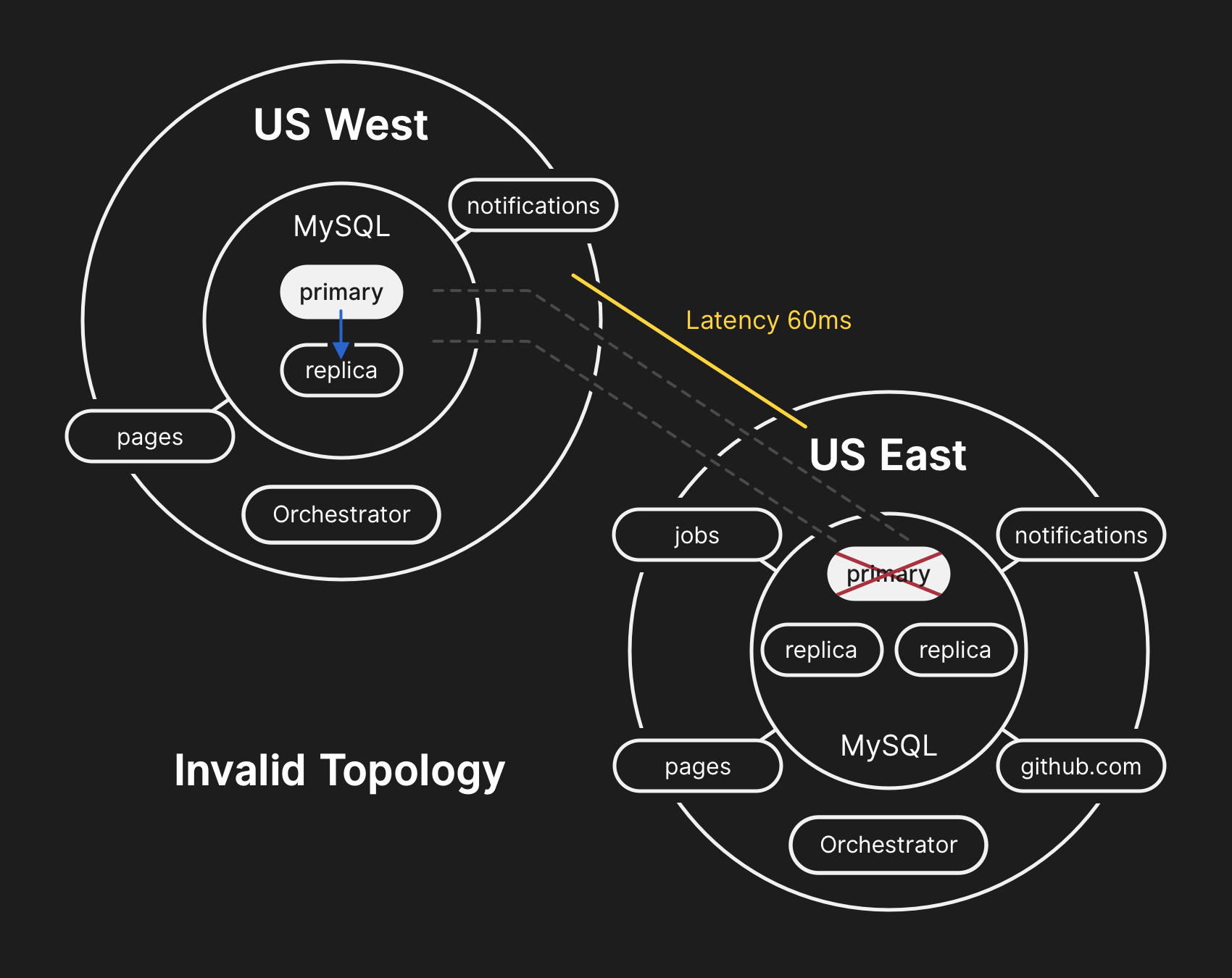
The database servers in the US East Coast data center contained a brief period of writes that had not been replicated to the US West Coast facility. Because the database clusters in both data centers now contained writes that were not present in the other data center, we were unable to fail the primary back over to the US East Coast data center safely.
동부 해안 데이터센터에 있는 데이터베이스 서버에는 아직 서부 해안 쪽으로 복제되지 않은 쓰기 작업들이 남아 있었습니다. 양쪽 데이터센터에 서로에게 있지 않은 쓰기 작업들이 남게된 것입니다. 이로 인해 동부 해안의 데이터센터에서는 주 데이터베이스 선정 작업이 실패하게 되었습니다.
2018 October 21 22:54 UTC
2018년 10월 21일 22:54 UTC
Our internal monitoring systems began generating alerts indicating that our systems were experiencing numerous faults. At this time there were several engineers responding and working to triage the incoming notifications. By 23:02 UTC, engineers in our first responder team had determined that topologies for numerous database clusters were in an unexpected state. Querying the Orchestrator API displayed a database replication topology that only included servers from our US West Coast data center.
내부 모니터링 시스템이 깃헙 시스템에 여러 문제가 발생했다고 알리기 시작했습니다. 이 때부터 많은 엔지니어들이 몰려 들어오는 알림을 분류하고 응답하기 시작했습니다. 23:02 UTC에 최초 대응팀의 엔지니어들은 데이터베이스 클러스터가 예상하지 않은 상태로 구성되어 있다고 판단했습니다. Orchestrator API의 쿼리 결과는 서부 해안 데이터센터의 서버들만 표시하고 있었습니다.
2018 October 21 23:07 UTC
2018년 10월 21일 23:07 UTC
By this point the responding team decided to manually lock our internal deployment tooling to prevent any additional changes from being introduced. At 23:09 UTC, the responding team placed the site into yellow status. This action automatically escalated the situation into an active incident and sent an alert to the incident coordinator. At 23:11 UTC the incident coordinator joined and two minutes later made the decision change to status red.
이 시점에 대응팀은 추가적인 변경 내용이 적용되는 것을 막기 위해 내부 배포 도구를 수동으로 잠그기로 결정했습니다. 23:09 UTC에 일부 장애 상황(yellow status)을 선언했습니다. 이는 현재 상태를 ‘실제 문제 상황’으로 승격시켜 자동으로 사건 담당자에게 알림이 가도록 했습니다. 23:11 UTC에 사건 담당자가 팀에 합류하여 2분 뒤 심각한 장애 상황(status red)으로 변경하였습니다.
2018 October 21 23:13 UTC
2018년 10월 21일 23:13 UTC
It was understood at this time that the problem affected multiple database clusters. Additional engineers from GitHub’s database engineering team were paged. They began investigating the current state in order to determine what actions needed to be taken to manually configure a US East Coast database as the primary for each cluster and rebuild the replication topology. This effort was challenging because by this point the West Coast database cluster had ingested writes from our application tier for nearly 40 minutes. Additionally, there were the several seconds of writes that existed in the East Coast cluster that had not been replicated to the West Coast and prevented replication of new writes back to the East Coast.
여러 데이터베이스 클러스터에 걸쳐 문제가 있음을 이 시점에서야 알게 되었습니다. 깃헙의 데이터베이스 엔지니어링 팀의 엔지니어들이 추가적으로 호출되었습니다. 그들은 각 클러스터에서 동부 해안 데이터베이스를 주 데이터베이스로 승격 시키고 구성을 복구 하기 위해 어떤 수작업이 필요한지 상황을 분석하기 시작했습니다. 이미 서부 해안의 데이터센터에 40여 분간 쓰기 작업이 이뤄졌기 때문에 작업하기가 매우 어려웠습니다. 그 뿐만 아니라 서부 해안에 복제되지 않고 동부 해안에서 복제가 막혀있는 몇 초간 작성되어 동부 해안에만 남아있는 쓰기 작업도 있었습니다.
Guarding the confidentiality and integrity of user data is GitHub’s highest priority. In an effort to preserve this data, we decided that the 30+ minutes of data written to the US West Coast data center prevented us from considering options other than failing-forward in order to keep user data safe. However, applications running in the East Coast that depend on writing information to a West Coast MySQL cluster are currently unable to cope with the additional latency introduced by a cross-country round trip for the majority of their database calls. This decision would result in our service being unusable for many users. We believe that the extended degradation of service was worth ensuring the consistency of our users’ data.
사용자 데이터의 기밀성과 무결성 유지는 깃헙의 최우선 과제입니다. 서부 해안에만 30분 이상 기록된 사용자 데이터를 안전하게 보존하기 위해 장애 조치를 내리는 것 외에는 다른 선택이 없었습니다. 하지만 동부 해안에서 실행되는 응용 프로그램들 중 서부 해안의 MySQL 클러스터에 쓰기에 의존하는 것들은 대부분의 데이터베이스 호출에 대륙을 왕복하는 지연 시간으로 인해 제대로 대처할 수 없는 상황이었습니다. 이로 인해 많은 사용자가 서비스를 이용할 수 없게 되었습니다. 하지만 서비스 장애 상황을 확대시켜서라도 데이터 일관성을 유지하는 것이 중요하다고 믿습니다.
2018 October 21 23:19 UTC
2018년 10월 21일 23:19 UTC
It was clear through querying the state of the database clusters that we needed to stop running jobs that write metadata about things like pushes. We made an explicit choice to partially degrade site usability by pausing webhook delivery and GitHub Pages builds instead of jeopardizing data we had already received from users. In other words, our strategy was to prioritize data integrity over site usability and time to recovery.
데이터베이스 클러스터의 상태를 조회한 결과 푸시와 같은 메타데이터를 기록하는 작업들을 중단해야 함이 분명해졌습니다. 사용자 데이터를 위태롭게 만드는 대신 웹 훅과 깃헙 페이지 생성을 일시 중지하여 사이트 사용성을 낮추는 명확한 선택을 했습니다. 즉, 사이트 가용성과 복구에 걸리는 시간보다 데이터 무결성에 더 높은 우선 순위를 부여하는 것이 저희의 전략이었습니다.
2018 October 22 00:05 UTC
2018년 10월 22일 00:05 UTC
Engineers involved in the incident response team began developing a plan to resolve data inconsistencies and implement our failover procedures for MySQL. Our plan was to restore from backups, synchronize the replicas in both sites, fall back to a stable serving topology, and then resume processing queued jobs. We updated our status to inform users that we were going to be executing a controlled failover of an internal data storage system.
사고 대응팀에 속한 엔지니어들은 데이터 불일치를 해결하기 위한 계획 수립과 더불어 MySQL 복원 프로시져를 구현하기 시작했습니다. 우선 백업으로부터 복원한 다음 양쪽 사이트에 있는 복제본을 동기화한 후, 데이터베이스 구성을 안정화하여 걸려 있는 작업들을 계속해서 수행하는 계획을 세웠습니다. 내부 데이터 저장 시스템을 절차에 따라 복원할 예정임을 사용자들에게 알렸습니다.
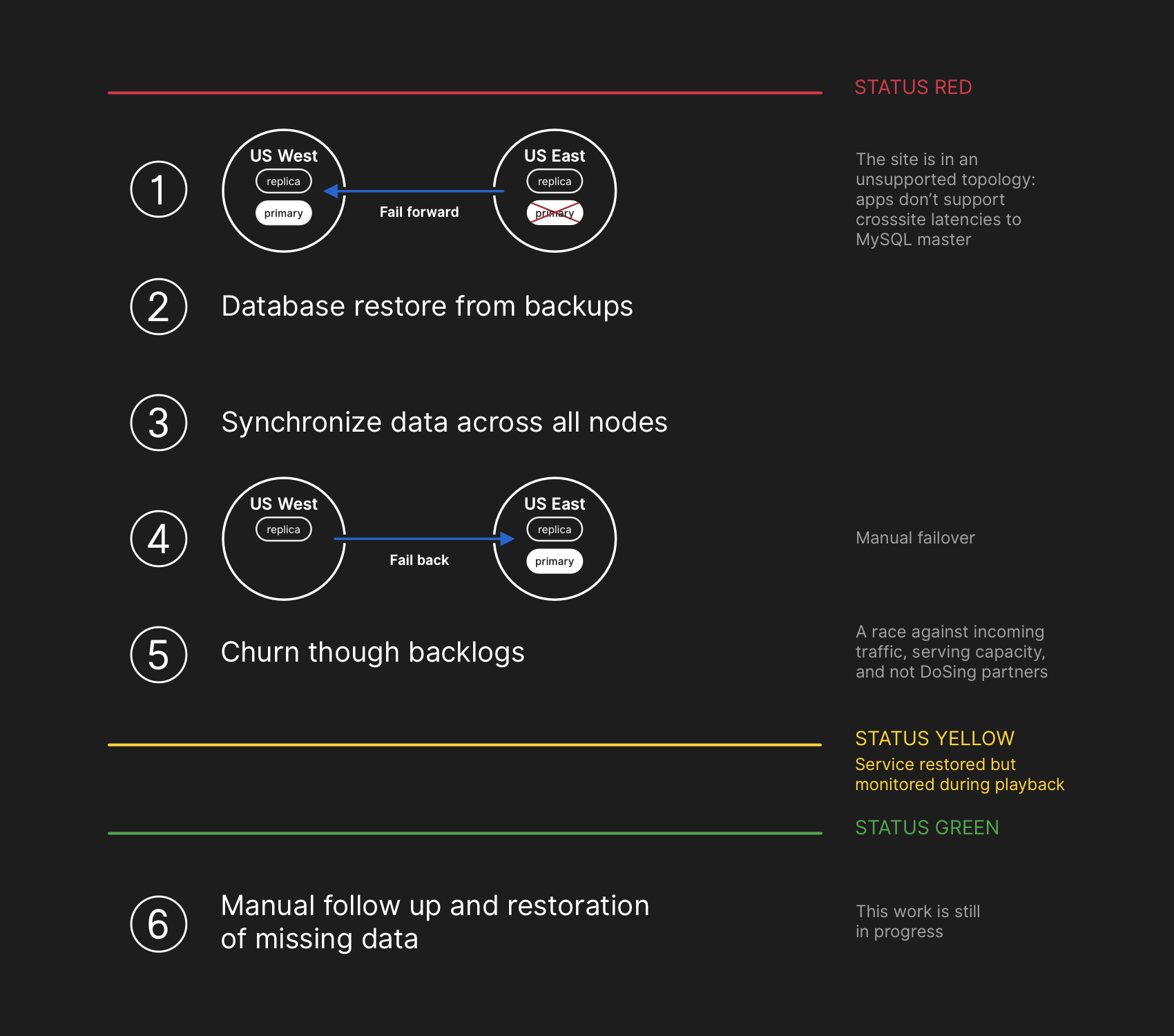
While MySQL data backups occur every four hours and are retained for many years, the backups are stored remotely in a public cloud blob storage service. The time required to restore multiple terabytes of backup data caused the process to take hours. A significant portion of the time was consumed transferring the data from the remote backup service. The process to decompress, checksum, prepare, and load large backup files onto newly provisioned MySQL servers took the majority of time. This procedure is tested daily at minimum, so the recovery time frame was well understood, however until this incident we have never needed to fully rebuild an entire cluster from backup and had instead been able to rely on other strategies such as delayed replicas.
수 년간 4시간 단위로 MySQL 데이터 백업이 이뤄지고 있었지만, 백업은 원격에 있는 공용 퍼블릭 클라우드의 BLOB 저장 서비스에 보관되어 있었습니다. 수 테라바이트에 이르는 여러 개의 백업 데이터를 복원하느라 많은 시간이 필요했습니다. 특히 원격 백업 서비스로부터 데이터를 전송해오는데 많은 시간이 소요되었습니다. 새로 인증된 MySQL 서버로 큰 백업 파일들을 불러와 압축 해제하고 무결성 검사를 한 후 준비해서 밀어넣는데 대부분의 시간을 썼습니다. 매일 테스트 하던 작업이라 복원하는데 얼마나 시간이 걸릴지는 예상할 수 있었지만, 이 사고가 나기 전까지는 백업으로부터 전체 클러스터를 완전히 새로 구성해본 적이 없었기 때문에 지연된 복제본 등의 다른 전략에 의존하는 수 밖엔 없었습니다.
2018 October 22 00:41 UTC
2018년 10월 22일 00:41 UTC
A backup process for all affected MySQL clusters had been initiated by this time and engineers were monitoring progress. Concurrently, multiple teams of engineers were investigating ways to speed up the transfer and recovery time without further degrading site usability or risking data corruption.
사고 영향을 받은 모든 MySQL 클러스터의 백업 프로세스가 시작되어 엔지니어들이 이를 모니터링 하고 있었습니다. 동시에 여러 팀의 엔지니어들이 데이터 손상이나 사이트 사용성을 저하시키지 않고 데이터 전송과 복원 시간을 줄일 방법을 조사하고 있었습니다.
2018 October 22 06:51 UTC
2018년 10월 22일 06:51 UTC
Several clusters had completed restoration from backups in our US East Coast data center and begun replicating new data from the West Coast. This resulted in slow site load times for pages that had to execute a write operation over a cross-country link, but pages reading from those database clusters would return up-to-date results if the read request landed on the newly restored replica. Other larger database clusters were still restoring.
몇몇 클러스터들은 동부 해안 데이터센터에서의 복원을 완료하고 서부 해안쪽에서의 새로운 데이터를 복제하기 시작했습니다. 대륙간 링크를 통해 쓰기 작업이 시작되느라 페이지 표시가 느려지기 시작했습니다. 대신 이 데이터베이스 클러스터에 속한 페이지를 읽을 때는 새롭게 복제된 곳에서 요청을 받아 최신의 데이터를 표시할 수 있게 되었습니다. 더 큰 데이터베이스 클러스터들은 여전히 복원중이었습니다.
Our teams had identified ways to restore directly from the West Coast to overcome throughput restrictions caused by downloading from off-site storage and were increasingly confident that restoration was imminent, and the time left to establishing a healthy replication topology was dependent on how long it would take replication to catch up. This estimate was linearly interpolated from the replication telemetry we had available and the status page was updated to set an expectation of two hours as our estimated time of recovery.
팀은 서부 해안 쪽에서 직접 복원할 수 있는 방법을 찾아내어, 원격 저장소에서 다운로드 받아 복원하느라 오래 걸리던 문제를 해결하고 곧 복원을 완료할 수 있다고 확신했습니다. 구성을 정상화시키는데는 이제 복제 과정이 얼마나 오래 걸리느냐에 달려있었습니다. 원격에서 복원하던 것에 비해 선형적으로 추정할 수 있게 되었으며, 상태 페이지를 복구까지 약 2시간 정도 남은 것으로 예상한다고 갱신할 수 있었습니다.
2018 October 22 07:46 UTC
2018년 10월 22일 07:46 UTC
GitHub published a blog post to provide more context. We use GitHub Pages internally and all builds had been paused several hours earlier, so publishing this took additional effort. We apologize for the delay. We intended to send this communication out much sooner and will be ensuring we can publish updates in the future under these constraints.
깃헙은 더 많은 맥락을 전달하기 위해 블로그 포스트를 올렸습니다. 이를 위해 내부적으로 깃헙 페이지를 사용하고 있었는데, 이 서비스는 몇 시간 전부터 정지되어 있었으므로 블로그를 발행하기 위해 몇몇 작업을 하느라 발행이 더 늦어졌습니다. 죄송합니다. 더 빨리 알렸어야 했는데 앞으로는 이런 상황 속에서도 더 빨리 상태를 알릴 수 있도록 하겠습니다.
2018 October 22 11:12 UTC
2018년 10월 22일 11:12 UTC
All database primaries established in US East Coast again. This resulted in the site becoming far more responsive as writes were now directed to a database server that was co-located in the same physical data center as our application tier. While this improved performance substantially, there were still dozens of database read replicas that were multiple hours delayed behind the primary. These delayed replicas resulted in users seeing inconsistent data as they interacted with our services. We spread the read load across a large pool of read replicas and each request to our services had a good chance of hitting a read replica that was multiple hours delayed.
모든 주 데이터베이스가 동부 해안 데이터센터로 다시 설정되었습니다. 이에 쓰기 작업이 물리적으로 같은 곳의 데이터베이스 서버로 이뤄져 사이트의 반응이 훨씬 나아졌습니다. 성능은 눈에 띄게 향상되었지만 여전히 읽기 데이터베이스 노드로 복제해야 수 시간의 분량이 남아 있는 상태였습니다. 지연된 복제로 인해 서비스를 이용하는 사용자들은 일관성 없는 데이터를 보게 되었습니다. 여러 읽기 복제본에 읽기 작업을 분산시키다보니 여전히 몇 시간이나 뒤쳐진 읽기 복제본에서 요청을 처리하는 경우가 많았습니다.
In reality, the time required for replication to catch up had adhered to a power decay function instead of a linear trajectory. Due to increased write load on our database clusters as users woke up and began their workday in Europe and the US, the recovery process took longer than originally estimated.
실제로 복제본이 따라잡는데 필요한 예상 시간은 선형적이라기 보다는 멱함수(power delay function)에 가까웠습니다. 유럽과 미국의 근무 시간이 시작되면서 데이터베이스 클러스터로의 쓰기 요청이 많아져 복구에 걸리는 시간은 예상했던 것보다 길어졌습니다.
2018 October 22 13:15 UTC
2018년 10월 22일 13:15 UTC
By now, we were approaching peak traffic load on GitHub.com. A discussion was had by the incident response team on how to proceed. It was clear that replication delays were increasing instead of decreasing towards a consistent state. We’d begun provisioning additional MySQL read replicas in the US East Coast public cloud earlier in the incident. Once these became available it became easier to spread read request volume across more servers. Reducing the utilization in aggregate across the read replicas allowed replication to catch up.
이제 깃헙의 최대 트래픽에 다다르고 있었습니다. 사고 대응팀에서는 어떻게 할 것인가에 대한 토론을 거쳤습니다. 복제에 걸리는 지연은 줄어들기는 커녕 증가하고 있음이 분명했습니다. 사고가 일어났을 초기에 동부 해안쪽의 공용 클라우드에 MySQL 읽기 사본을 추가해둔 상태였습니다. 이것을 사용할 수 있게 되면 더 많은 서버에 읽기 요청을 분산하기 용이해집니다. 전체적인 사용율을 낮추면 복제본이 따라잡기도 더 쉬워질 것입니다.
2018 October 22 16:24 UTC
2018년 10월 22일 16:24 UTC
Once the replicas were in sync, we conducted a failover to the original topology, addressing the immediate latency/availability concerns. As part of a conscious decision to prioritize data integrity over a shorter incident window, we kept the service status red while we began processing the backlog of data we had accumulated.
복제본이 동기화되는 대로 바로 원래 구성으로 돌아가게 장애 조치를 취하고 바로 지연과 가용성 문제를 다뤘습니다. 사고 시간을 줄이는 것보다 데이터 무결성을 최우선 한다는 결정하에, 백로그를 처리하는 중에도 여전히 심각한 장애 상황(status red)을 유지하였습니다.
2018 October 22 16:45 UTC
2018년 10월 22일 16:45 UTC
During this phase of the recovery, we had to balance the increased load represented by the backlog, potentially overloading our ecosystem partners with notifications, and getting our services back to 100% as quickly as possible. There were over five million hook events and 80 thousand Pages builds queued.
이 복구 단계에서는 백로그에 의해 증가하는 부하를 다루는 것과 깃헙 생태계의 파트너들에 보내는 알림(notification)들, 그리고 서비스를 최대한 빠르게 100% 복원하는 것 사이에서 균형을 잡아야 했습니다. 500만개 이상의 훅 이벤트와 8만 개 이상의 페이지 생성 작업이 기다리고 있었습니다.
As we re-enabled processing of this data, we processed ~200,000 webhook payloads that had outlived an internal TTL and were dropped. Upon discovering this, we paused that processing and pushed a change to increase that TTL for the time being.
이 데이터 처리를 다시 시작하면서 내부적으로 설정된 제한시간(TTL)을 초과하여 취소된 20만개에 가까운 웹훅 요청을 처리하였습니다. 이를 알게되어 처리를 일단 중단하고 임시로 제한시간을 늘려 다시 작업을 진행하도록 했습니다.
To avoid further eroding the reliability of our status updates, we remained in degraded status until we had completed processing the entire backlog of data and ensured that our services had clearly settled back into normal performance levels.
상태 알림을 다시 돌리는 일이 없게끔, 백로그를 모두 처리하고 서비스가 완전히 정상적인 수준으로 명확하게 회복될 때까지 장애 상태를 유지하도록 했습니다.
2018 October 22 23:03 UTC
2018년 10월 22일 23:03 UTC
All pending webhooks and Pages builds had been processed and the integrity and proper operation of all systems had been confirmed. The site status was updated to green.
밀려있던 모든 웹훅과 페이지 생성 작업이 처리되었으며 시스템 무결성과 작동이 완전히 확인되었습니다. 드디어 정상 상태로 돌아왔습니다.
Next steps
앞으로 할 일
Resolving data inconsistencies
데이터 부정합 해결
During our recovery, we captured the MySQL binary logs containing the writes we took in our primary site that were not replicated to our West Coast site from each affected cluster. The total number of writes that were not replicated to the West Coast was relatively small. For example, one of our busiest clusters had 954 writes in the affected window. We are currently performing an analysis on these logs and determining which writes can be automatically reconciled and which will require outreach to users. We have multiple teams engaged in this effort, and our analysis has already determined a category of writes that have since been repeated by the user and successfully persisted. As stated in this analysis, our primary goal is preserving the integrity and accuracy of the data you store on GitHub.
복구 과정에서 주 사이트에서 서부 해안 사이트로 복제되지 않은 쓰기 작업을 담고 있는 MySQL 바이너리 로그(binlog)를 영향을 받은 클러스터로부터 캡처했습니다. 서부로 복제되지 않은 총 쓰기 작업은 상대적으로 적었습니다. 가장 바쁜 클러스터에서도 영향을 받은 윈도우에 954개의 쓰기 작업이 있을 뿐이었습니다. 저희는 이러한 로그에 대한 분석을 진행하고 있으며, 자동적으로 조정될 쓰기 작업과 그렇지 않은 사용자의 개입이 필요한 것들을 분류하고 있습니다. 이 작업을 위해 여러 팀이 노력하고 있으며, 사용자가 반복하여 수행해 성공적으로 쓰여진 작업에 대한 분석은 이미 완료되었습니다. 이 글에서 앞서 언급했던 대로 저희의 최우선 목표는 사용자의 데이터 무결성과 정합성을 유지하는 것입니다.
Communication
커뮤니케이션
In our desire to communicate meaningful information to you during the incident, we made several public estimates on time to repair based on the rate of processing of the backlog of data. In retrospect, our estimates did not factor in all variables. We are sorry for the confusion this caused and will strive to provide more accurate information in the future.
사건이 진행되는 동안에 저희는 의미있는 정보를 전달하고자, 데이터 백로그 처리율에 근거하여 복원에 필요한 추정 시간을 여러 번 발표했었습니다. 돌이켜보면, 저희의 예상은 모든 변수를 고려하지 못했습니다. 이로 인해 혼란을 야기했던 점에 대해 죄송스러운 마음을 전하며, 앞으로는 더 정확한 정보를 제공하기 위해 노력하겠습니다.
Technical initiatives
기술적 개선안
There are a number of technical initiatives that have been identified during this analysis. As we continue to work through an extensive post-incident analysis process internally, we expect to identify even more work that needs to happen.
분석을 진행하며 확인된 여러 기술적 개선안들이 있습니다. 더 넓은 사후 분석 작업을 통해 앞으로 일어날 수 있는 더 많은 일을 확인할 수 있을 것으로 기대합니다.
Adjust the configuration of Orchestrator to prevent the promotion of database primaries across regional boundaries. Orchestrator’s actions behaved as configured, despite our application tier being unable to support this topology change. Leader-election within a region is generally safe, but the sudden introduction of cross-country latency was a major contributing factor during this incident. This was emergent behavior of the system given that we hadn’t previously seen an internal network partition of this magnitude.
We have accelerated our migration to a new status reporting mechanism that will provide a richer forum for us to talk about active incidents in crisper and clearer language. While many portions of GitHub were available throughout the incident, we were only able to set our status to green, yellow, and red. We recognize that this doesn’t give you an accurate picture of what is working and what is not, and in the future will be displaying the different components of the platform so you know the status of each service.
In the weeks prior to this incident, we had started a company-wide engineering initiative to support serving GitHub traffic from multiple data centers in an active/active/active design. This project has the goal of supporting N+1 redundancy at the facility level. The goal of that work is to tolerate the full failure of a single data center failure without user impact. This is a major effort and will take some time, but we believe that multiple well-connected sites in a geography provides a good set of trade-offs. This incident has added urgency to the initiative.
We will take a more proactive stance in testing our assumptions. GitHub is a fast growing company and has built up its fair share of complexity over the last decade. As we continue to grow, it becomes increasingly difficult to capture and transfer the historical context of trade-offs and decisions made to newer generations of Hubbers.
Orchestrator의 설정을 조정하여 지역 경계를 넘는 주 데이터베이스 승격 작업을 방지할 예정입니다. Orchestrator는 애플리케이션 쪽에서 변경된 구성을 받아들일 수 없는 상황임에도 불구하고 설정된 대로 동작했습니다. 지역 내에서의 승격 작업은 일반적으로 안전하지만, 대륙간 지연 시간이 갑자기 발생한 것이 이번 사고의 주요 원인이 되었습니다. 내부 네트워크가 단절되는 수준에서는 발견하지 못했던 시스템의 돌발 상황이었습니다.
새로운 상태 보고 체계로의 전환을 더 가속화 하여 의견을 나눌 수 있는 소통 창구의 제공과 현재 상황에 대한 더 명확한 전달이 가능하도록 할 예정입니다. 사고가 발생한 상황에서도 깃헙의 대부분이 가용했음에도 불구하고, 상태를 초록, 노랑 그리고 빨강으로 표현할 수 밖에 없었습니다. 이것으로는 어떤 것들이 동작하는지에 대한 정확한 상황을 전달할 수 없음을 깨닫고, 앞으로는 플랫폼의 서로 다른 부분에 대해 각각의 상태를 표시할 수 있도록 하겠습니다.
이 사건이 발생하기 몇 주 전에, 여러 데이터센터에서 active/active/active 상태로 깃헙 트래픽을 처리할 수 있도록 하는 전사적인 엔지니어링 개선 작업을 시작했습니다. 이 프로젝트의 목표는 저수준에서의 N+1 이중화를 지원하는데 있습니다. 하나의 데이터센터가 완전히 동작하지 않는 상황에서도 사용자에게 영향을 미치지 않는 수준을 목표로 합니다. 많은 노력과 시간이 소요되겠지만, 지리적으로 잘 연결된 여러 사이트가 구성될 수 있을 것입니다. 이번 사건을 통해 우선순위를 높여 작업하게 되었습니다.
보다 적극적으로 상황을 가정하여 테스트할 예정입니다. 깃헙은 지난 10년간 빠르게 성장하고 있으며 그만큼 복잡도도 빠르게 증가하였습니다. 깃헙이 계속 성장함에 따라 새로운 세대의 깃허버(Hubbers)들에게 트레이드 오프와 의사 결정에 대한 역사적인 맥락을 전달하기가 어려워지고 있습니다.
Organizational initiatives
조직적 개선안
This incident has led to a shift in our mindset around site reliability. We have learned that tighter operational controls or improved response times are insufficient safeguards for site reliability within a system of services as complicated as ours. To bolster those efforts, we will also begin a systemic practice of validating failure scenarios before they have a chance to affect you. This work will involve future investment in fault injection and chaos engineering tooling at GitHub.
이 사고를 계기로 사이트 가용성에 대한 사고 방식 자체가 달라졌습니다. 깃헙과 같이 복잡한 서비스 시스템에서는 엄격한 운영 제어나 개선된 응답 시간만으로는 가용성을 유지하기에 충분치 않음을 알게 되었습니다. 이러한 노력에 더해, 사용자에게 문제가 될만한 장애 시나리오를 검증하는 체계적인 연습을 시작할 예정입니다. 이 작업에는 깃헙의 카오스 엔지니어링 툴링과 결함 주입(fault injection)에 대한 투자가 포함됩니다.
Conclusion
결론
We know how much you rely on GitHub for your projects and businesses to succeed. No one is more passionate about the availability of our services and the correctness of your data. We will continue to analyze this event for opportunities to serve you better and earn the trust you place in us.
여러분의 프로젝트와 사업의 성공에 깃헙이 얼마나 큰 책임을 지고 있는지 잘 알고 있습니다. 그 누구도 저희 만큼 서비스의 가용성과 데이터의 정합성에 대해 열정을 가지고 있지 않습니다. 더 나은 서비스와 신뢰를 얻기 위해 이번 사건에 대한 분석을 계속해나갈 예정입니다.

