Simple Made Easy
쉽게 풀이한 단순함
- Conference: Strange Loop 2011 - Sept 2011
- Video: https://www.youtube.com/watch?v=SxdOUGdseq4
- 컨퍼런스: Strange Loop 2011 - 2011년 9월
- 비디오: https://www.youtube.com/watch?v=SxdOUGdseq4

Hi. So who is ready for some more category theory?
안녕하세요. 카테고리 이론에 대해서 배우실 준비가 되었나요?
[Audience applause]
[관객들의 박수]
You're all in the wrong room.
모두 강의실을 잘못 찾아오셨네요. (농담)
[Audience laughter]
[관객들의 웃음]
This talk I hope seems deceptively obvious. One of the things that's great about this conference is this is a pretty cutting-edge crowd. A lot of you are adopting new technologies. A lot of you are doing functional programming. And you may be nodding, saying yeah, yeah, yeah through parts of this. And if some of it is familiar, that's great.
제 발표 주제가 수상할 정도로 뻔해 보이시죠. 이 컨퍼런스의 좋은 점 하나는 여기 계신 많은 분들이 산업의 선두주자라는 것입니다. 새로운 기술을 받아들이고, 함수형 프로그래밍을 하고 계시겠지요. 컨퍼런스를 즐기면서 “그렇지, 그렇지” 하면서 고개를 끄덕이는 분들이 많을 겁니다. 그리고 이미 몇몇 주제를 잘 알고 계신다면, 훌륭하군요.
On the other hand, I think that I would hope that you would come away from this talk with some tools you could use to help conduct a similar kind of discussion to this talk with other people that you're trying to convince to do the right thing.
한편으로 저는 여러분이 이 강연에서 몇 가지 도구를 얻어 가시길 바랍니다. 이 도구들은, 앞으로 여러분이 강연을 하거나 다른 사람들을 올바른 방향으로 설득할 때 아주 유용하게 쓰일 겁니다.

So, I'll start with an appeal to authority. Simplicity is a prerequisite for reliability. I certainly agree with this. I don't agree with everything Dijkstra said, and I think he might have been very wrong about proof in particular. But I think he's right about this. We need to build simple systems if we want to build good systems. I don't think we focus enough on that.
권위에 호소하면서 시작해보죠. 데이크스트라는, 신뢰성의 전제 조건은 단순성이라고 말했습니다. 저는 이 말에 전적으로 동의합니다. 제가 데이크스트라의 모든 말에 동의하지는 않습니다. 특히 증명(proof)에 대해서는 그가 아주 잘못 짚었다고 생각합니다. 하지만 단순성에 대해서는 그가 옳다고 생각해요. 좋은 시스템은 단순합니다. 우리는 이 사실을 충분히 주목하지 않고 있어요.

I love word origins. They're tremendous fun. One of the reasons why they're fun is because words eventually come to mean whatever we all accept them to mean. You know, whatever is commonly understood to be the meaning is what it means. And it's often interesting to say, well, I wish I could; I wish we could go back to what it really means and use that. And I think there's a couple of words that I'm going to use in this talk that I would love for you to come away knowing the origins of and try to use more precisely, especially when talking about software.
저는 어원을 알아내는 걸 정말 좋아해요. 왜냐하면 우리가 단어의 의미를 수용하는 대로, 결국 그 의미를 지니게 되기 때문입니다. 여러분도 알다시피 일반적으로 단어란 우리가 이해하는 대로, 의미를 지니게 됩니다. 그래서 종종 이렇게 말하기도 하죠. “그 단어를, 그 단어가 가진 진정한 의미로 사용할 수 있으면 좋겠어요.” 저도 이 강연에서 사용할 단어가 몇 개 있는데, 특히 소프트웨어에 대해 이야기할 때 그 어원을 알아서 좀더 정확하게 사용하고 싶습니다.
So, the first word is simple. And the roots of this word are sim and plex, and that means one-fold or one braid or twist. And that characteristic about being about one literally fold or twist, of course one twist, what's one twist look like? No twists, right, actually.
첫 번째로, ‘단순한(simple)’이란 단어를 살펴봅시다. 이 단어의 어원은 ‘sim’과 ‘plex’입니다. ‘sim’은 ‘하나’라는 의미고, ‘plex’는 ‘겹치다’ 또는 ‘엮다’라는 뜻입니다. 그래서, 말 그대로 줄 하나를 겹치거나 엮었다면... 줄 하나를 엮으면 어떻게 생겼을까요? 그대로죠, 그렇죠?
And the opposite of this word is complex, which means braided together or folded together. Being able to think about our software in terms of whether or not it's folded together is sort of the central point of this talk.
‘단순한’의 반대말은 ‘복잡한(complex)’입니다. 말 그대로 함께(com) 겹쳤거나 얽혀 있다는 뜻이죠. 우리의 소프트웨어가 ‘겹쳐’ 있는지 생각해보는 것이 이 강연의 핵심이라고 할 수 있습니다.
The other word we frequently use interchangeably with ‘simple’ is the word ‘easy’. And the derivation there is to a French word, and the last step of this derivation is actually speculative, but I bought it because it serves this talk really well, and that is from the Latin word that is the root of ‘adjacent’, which means to lie near and to be nearby. And the opposite is hard. Of course, the root of hard has nothing to do with lying near. It doesn't mean lie far away. It actually means like strong or tortuously so.
우리는 ‘simple(간단한)’을 대신하는 단어로 ‘easy(쉬운)’를 자주 사용합니다. ‘easy’는 프랑스 단어에서 파생됐기에 정확한 어원은 추측할 수밖에 없습니다. 제가 지금처럼 추측하는 이유는 이 강의에 잘 들어맞기 때문입니다. ‘ease(쉽다)’는 ‘adjacent(인접하다)’라는 라틴어에서 유래한 것으로, 근처에 눕거나 가까이 있다는 의미입니다. 반대말은 ‘hard(어려운)’입니다. 물론, ‘hard’의 어원은 ‘가까이 있다’라는 의미와 상관이 없습니다. 따라서 ‘hard’가 멀리 떨어져 있다는 의미는 아닙니다. ‘강한’ 혹은 ‘힘들다’라는 의미입니다.

So, if we want to try to apply ‘simple’ to the kinds of work that we do, we're going to start with this concept of having ‘one braid’. And look at it in a few different dimensions. I thought it was interesting in Eric's talk to talk about dimensions because it's definitely a big part of doing design work. And so, if we want to look for simple things, we want to look for things that have sort of ‘one’ of something. They do, they have ‘one’ role. They fulfill ‘one’ task or job. They're about accomplishing sort of ‘one’ objective. They might be about ‘one’ concept like ‘security’.
이제, 우리 업무에 단순함을 적용하기로 합시다. 줄 하나를 엮는다는 개념이 따라옵니다. 이걸 조금 다른 차원(dimension)에서 바라봅시다. 저는 에릭의 발표에서 치수(dimension)에 대한 이야기가 흥미로웠습니다. 왜냐하면 치수 측정은 프로그래밍 디자인에서 중요한 부분이기 때문입니다. 어쨌든 단순함을 얻고 싶다는 말은, 딱 하나로 구성된 무언가를 얻고 싶다는 뜻입니다. 그것은 한 역할만 할 것이고, 하나의 임무나 일을 수행하며, 한 목표만 달성합니다. ‘보안’처럼, 딱 한 종류의 개념입니다.
And sort of overlapping with that is they may be about a particular dimension of the problem that you're trying to solve. The critical thing there, though, is that when you're looking for something that's simple, you want to see it have focus in these areas. You don't want to see it combining things.
이는 여러분이 해결하려는 문제의 특정한 측면(dimension)일 수 있습니다. 여러분이 단순함을 얻고 싶다면, 이 특정 부분에 주목해야 합니다. 여러가지를 합쳐서 보지 말고요.
On the other hand, we can't get too fixated about ‘one’. In particular, simple doesn't mean that there's only ‘one’ of them. Right? It also doesn't mean an interface that only has ‘one’ operation. So, it's important to distinguish cardinality, right, counting things from actual ‘interleaving’. What matters for simplicity is that there is no ‘interleaving’, not that there's only one thing, and that's very important.
반면에, ‘하나’라는 것에 너무 집착해서도 안 됩니다. 특히, 단순하다고 해서 ‘하나’만 존재한다는 말은 아닙니다. 기능이 하나라는 의미도 아닙니다. 카디널리티 즉 기능의 개수와 실제 뒤섞임(interleaving)을 구별해야 합니다. 단순함에서 중요한 것은 뒤섞이지 않았다는 점이지, 기능이 하나뿐이라는 점이 아닙니다. 이는 매우 중요합니다.
Okay, the other critical thing about simple, as we've just described it, right, is if something is interleaved or not, that's sort of an objective thing. You can probably go and look and see. I don't see any connections. I don't see anywhere where this ‘twist’ was something else, so simple is actually an objective notion. That's also very important in deciding the difference between simple and easy.
좋아요. 단순함에서 또다른 중요한 점이 있습니다. 무언가가 뒤섞여있는지 여부가 어느정도 객관적이란 사실입니다. 직접 들여다보면서 ‘연결된 부분이 보이지 않아’라거나, ‘이 엮임이었던 부분을 못 찾겠어’라고 말할 수 있습니다. 여기서 알 수 있듯이, 단순함은 사실 객관적인 개념입니다. 이 점은 ‘단순함’과 ‘쉬움’을 구분할 때도 매우 중요합니다.

So let's look at easy. I think this notion of nearness is really, really cool. In particular, obviously there's many ways in which something can be near. Right? There's sort of the physical notion of being near. Right? Is something, you know, right there. And I think that's where the root of the word came from. You know, this is easy to obtain because it's nearby. It's not in the next town. I don't have to take a horse or whatever to go get to it. We don't have the same notion of physicality necessarily in our software, but we do sort of have, you know, our own hard drive or our own toolset, or it's sort of the ability to make things physically near by getting them through things like installers and stuff like that.
이제, ‘easy(쉬운)’라는 단어를 살펴봅시다. 저는 가까움이라는 개념이 정말 멋지다고 생각합니다. 가깝다는 건 다양하게 해석할 수 있습니다. 물리적인 개념이기도 하죠. 여기 있다는 것 말이에요. 이렇게 ‘easy’의 어원이 시작된 것 같아요. 가까이 있기에 ‘쉽게’ 구할 수 있다는 말이죠. 옆 동네가 아니라요. 그걸 얻기 위해 말을 타고 갈 필요가 없죠. 물론 소프트웨어에서 ‘가까움’의 물리적인 개념이 동일하게 적용되지는 않습니다. 하지만 설치 관리자 등을 통해 내 하드드라이브에 저장한다거나 도구상자에 넣어서 가까워졌다는다는 식으로 생각할 수 있습니다.
The second notion of nearness is something being near to our understanding, right, or in our current skill set. And I don't mean in this case near to our understanding meaning a capability. I mean literally near something that we already know. So, the word in this case is about being familiar.
가까움의 두 번째 개념은 우리의 지식에 가까운 것입니다. 또는 우리가 지닌 기술에요. 우리의 ‘재능’에 가깝다는 뜻이 아닙니다. 말 그대로 우리가 이미 알고 있는 것 ‘근처’라는 뜻이지요. 따라서 이 경우에는 친숙함을 의미합니다.
I think that, collectively, we are infatuated with these two notions of ‘easy’. We are just so self-involved in these two aspects. it's hurting us tremendously. Right? All we care about is, you know, can I get this instantly and start running it in five seconds? It could be this giant hairball that you got, but all you care is, you know, can you get it.
그동안 우리는 ‘easy(쉬운)’의 두 가지 개념에 심취했어요. 여기에만 너무 매몰되다 보니 나약해졌어요. 무언가를 봤을 때 ‘지금 즉시 설치해서 5초 안에 실행할 수 있을까?’만 고려하는 거죠. 우리가 다루는 문제는 커다란 털 뭉치처럼 엉켜 있는데, 우리는 쉽게 가져다 쓸 수 있는지만 따진다는 말입니다.
In addition, we're fixated on, oh, I can't; I can't read that. Now I can't read German. Does that mean German is unreadable? No. I don't know German. So, you know, this sort of approach is definitely not helpful. In particular, if you want everything to be familiar, you will never learn anything new because it can't be significantly different from what you already know and not drift away from the familiarity.
또한, ‘읽을 수 없음’에도 메여 있어요. 저는 독일어를 읽을 줄 모릅니다. 그렇다고 해서 독일어가 해석 불가능한 언어인가요? 아니죠. 제가 독일어를 모를 뿐입니다. 그러니까 이런 식의 접근은 도움이 되지 않습니다. 모든 것이 익숙한 환경을 원한다면 아무것도 새로 배울 수 없습니다. 왜냐하면 이미 알고 있는 것과 크게 다르지도 않고 낯설지도 않을 테니까요.
There's a third aspect of being ‘easy’ that I don't think we think enough about that's going to become critical to this discussion, which now is, being near to our capabilities. And we don't like to talk about this because it makes us uncomfortable because what kind of capabilities are we talking about? If we're talking about easy in the case of violin playing or piano playing or mountain climbing or something like that, well, you know, I don't personally feel bad if I don't play the violin well because I don't play the violin at all.
‘easy(쉬운)’의 세 번째 측면은 우리가 충분히 생각하지 않는 부분입니다. 하지만 굉장히 중요합니다. 그것은 바로, 우리가 가진 ‘재능’에 가까운 것입니다. 사실 우리는 이런 이야기하는 것을 좋아하지 않습니다. 불편하게 느끼기까지 하죠. 우리가 지금 얘기하는 재능이 어떤거죠? 바이올린 연주나 피아노 연주, 등산을 생각해볼까요? 저는 바이올린을 연주하지 않기 때문에 바이올린을 잘 연주할 수 없어도 기분 나쁘지 않습니다.
But the work that we're in is conceptual work, so when we start talking about something being outside of our capability, well, you know, it really starts trampling on our egos in a big way. And so, you know, due to a combination of hubris and insecurity, we never really talk about whether or not something is outside of our capabilities. It ends up that it's not so embarrassing after all because we don't have tremendously divergent abilities in that area.
하지만 우리가 하는 일은 개념과 관련된 작업입니다. 그래서 우리 능력 밖의 이야기를 하면, 자존심이 크게 상합니다. 자만심과 불안함이 합쳐진 결과, 우리는 무엇이 우리 능력을 벗어나는지를 결코 이야기하지 않습니다. 어떤 분야에 대단한 재능을 갖지 않았기 때문에, 부끄럽지 않다고 결론 짓고 끝내는 거죠.
The last thing I want to say about ‘easy’ and the critical thing to distinguish it from ‘simple’ is that easy is relative. Right? Playing the violin and reading German are really hard for me. They're easy for other people, certain other people. So, unlike ‘simple’, where we can go and look for ‘interleavings’, look for braiding, ‘easy’ is always going to be, you know, easy for whom, or hard for whom? It's a relative term.
마지막으로, 쉬움과 단순함을 구별하는 가장 중요한 요소는 상대성입니다. 예를 들어, 바이올린 연주와 독일어 문장을 읽는 것은 저에겐 정말 어려운 일입니다. 어떤 사람들에겐 쉽겠지만요. 뒤섞이거나 꼬인 부분을 봤을 때 단순함을 어겼다고 할 수 있는 것과는 달리, 쉬움은 누구에게 쉽다거나, 누구에게 어렵다는 말로 이어집니다. 쉬움은 상대적인 용어입니다.
The fact that we throw these things around sort of casually saying, oh, I like to use that technology because it's ‘simple’, and when I'm saying ‘simple’, I mean ‘easy’. And when I am saying ‘easy’, I mean because I already know something that looks very much alike that. It's how this whole thing degrades, and we can never have an objective discussion about the qualities that matter to us in our software.
우리가 무심코 ‘저는 그 기술이 단순해서 사용했어요.’라고 말한다면 이건 쉽다는 뜻이 됩니다. 그리고 제가 ‘쉽다’고 말할 때는, 비슷한 무언가를 이미 알고 있다는 뜻이 되고요. 이런 식으로 점점 쇠퇴합니다. 그러다보니 소프트웨어에서 중요한 품질에 대해서는 정작 논의하지 못합니다.

So, what's one critical area where we have to distinguish these two things and look at them from a perspective of them being ‘easy’ and being ‘simple’? It has to do with constructs and artifacts. Right? We program with constructs. We have programming languages. We use particular libraries, and those things, in and of themselves, when we look at them, like when we look at the code we write, have certain characteristics in and of themselves.
그렇다면 이 둘을 구분해야만 하는 중요한 영역은 무엇일까요? 쉽고 단순한 관점으로 살펴보아야만 하는 영역 말입니다. 그건 바로 도구(constructs)와 결과물(artifacts)입니다. 우리는 도구를 사용해서 프로그래밍합니다. 프로그래밍 언어로요. 어떤 라이브러리 같은 걸 사용해서요. 라이브러리나 우리가 작성한 코드를 들여다보면 일종의 특징을 발견할 수 있습니다.
But we're in a business of artifacts. Right? We don't ship source code, and the user doesn't look at our source code and say, "Ah, that's so pleasant." Right? No? They run our software, and they run it for a long period of time. And, over time, we keep glomming more stuff on our software. All that stuff, the running of it, the performance of it, the ability to change it all is an attribute of the artifact, not the original construct.
하지만 우리는 또한 결과물을 만드는 비즈니스에 속해 있습니다. 우리가 소스코드를 배송하면 사용자들이 그걸 보면서 만족하는 게 아니죠. 그렇지 않나요? 사용자들은 우리 소프트웨어를 실행하고 오랫동안 사용하죠. 시간이 가면서 우리는 다른 기능들을 추가합니다. 이런 기능을 실행하고 보여주고 수정하는 과정은 결과물의 속성입니다. 도구가 아니라요.
But again, here we still focus so much on our experience of the use of the construct. Oh, look; I only had to type 16 characters. Wow! That's great. No semicolons or things like that. This whole notion of sort of programmer convenience, again, we are infatuated with it, not to our benefit.
하지만 우리는 여전히 도구의 사용 경험에만 주목합니다. “오 열여섯 글자만 입력했을 뿐인데, 멋지네요! 세미콜론 같은 것도 없어요.” 이런 기능들은 프로그래밍을 더 편하게 만들어주는데, 우리는 이런 편의성에만 몰입합니다. 프로그래밍이 만들어내는 사업적 이익이 아니라요.
On the flipside it gets even worse. Our employers are also infatuated with it. Right? Those first two meanings of ‘easy’, what do they mean? Right? If I can get another programmer in here, right? And they look at your source code, and they think it's familiar, right? And they already know the ‘toolkit’, right? So, it's near at hand. They've always had the same tool in their toolkit. They can read it. I can replace you. It's a breeze, especially if I ignore the third notion of easy, right, which is whether or not anybody can understand your code, right, because they don't actually care about that. They just care that somebody can go sit in your seat, start typing.
동전의 반대편 역시 나쁘긴 마찬가집니다. 고용주들도 여기에 심취해 있어요. ‘easy’의 처음 두 가지 의미가 뭐였죠? 어떤 프로그래머를 여기 불러왔다고 하죠. 여러분의 소스코드를 보고 친숙하게 느낄테죠. 그들은 이미 도구상자를 알고 있죠. (손에) 가깝다는 말입니다. 그들의 도구 모음에는 항상 똑같은 도구가 들어 있고요. 코드를 읽을 수 있으니 여러분을 대신할 수 있습니다. 식은 죽 먹기죠. 특히나 제가 ‘easy’의 세 번째 개념을 무시한다면요. 세 번째 개념은 코드를 이해할 수 있냐는 것입니다. 왜냐하면 고용주들은 이런 걸 신경쓰지 않기 때문이죠. 그저 누군가 여러분의 자리에 앉아서 키보드를 두드릴 수 있는지만 고려합니다.
So again, as sort of business owners, there's sort of, again, the same kind of focus on those first two aspects of ‘easy’ because it makes programmers replaceable. So, we're going to contrast this with the impacts of long-term use. Right? What does it mean to use this long term? And what's there? What's there is all the meat. Right?
저도 경영주이기에 다시 말씀드리지만, ‘easy’의 처음 두 가지 측면은 관점이 같습니다. 프로그래머를 ‘쉽게’ 교체하는 것 말이죠. 이 관점을 장기간 유지했을 때의 영향력도 따져봅시다. 이런 방식을 오랫 동안 사용한다는 건 어떤 의미일까요? 여기서 핵심이 뭘까요?
Does the software do what it's supposed to do? Is it of high quality? Can we rely on it doing what it's supposed to do? Can we fix problems when they arise? And if we're given a new requirement, can we change it? These things have nothing to do with the construct, as we typed it in, or very little to do with it, and have a lot to do with the attributes of the artifact. We have to start assessing our constructs based around the artifacts, not around the look and feel of the experience of typing it in or the cultural aspects of that.
소프트웨어가 제대로 작동하나요? 품질이 좋은가요? 우리가 소프트웨어를 믿을 수 있을까요? 문제가 발생하면 고칠 수 있나요? 새 요구사항이 생기면 반영할 수 있을까요? 이것들은 우리가 사용한 도구와는 아무 상관이 없습니다. 대신 결과물의 속성에 깊이 관련되죠. 결과물을 기준으로, 도구를 평가해야 합니다. 소스코드의 겉모습이나 문화적 측면이 아니라요.

So let's talk a little bit about limits. Oh, look; it does move. This is just supposed to sort of lull you into this state where everything I say seems true.
자! 이제 한계에 대해 이야기해봅시다. 오, 보세요. 움직이네요. 이걸로 여러분을 홀리면 좋겠네요. 제 말이 모두 진실처럼 보이게 말이예요.
[Audience laughter]
[관객들의 웃음]
Because I can't use monads to do that.
모나드로는 안 먹힐 테니까요.
[Audience laughter]
[관객들의 웃음]
This stuff is pretty simple logic, right? How can we possibly make things that are reliable that we don't understand? It's very, very difficult. I think Professor Sussman made a great point saying there's going to be this tradeoff, right? As we make things more flexible and extensible and dynamic in some possible futures for some kinds of systems, we are going to make a tradeoff in our ability to understand their behavior and make sure that they're correct. But for the things that we want to understand and make sure are correct, we're going to be limited. We're going to be limited to our understanding.
여기 보이는 이야기는 간단합니다. 우리가 이해하지도 못하면서 믿을 만한 물건을 만들 수 있나요? 그건 정말 정말 어렵죠. 제럴드 제이 서스먼 교수님이 지적했듯, 상충되는 면이 있습니다. 어떤 시스템을 유연하고 확장 가능하면서 역동적으로 만든다고 합시다. 작동 방식을 이해하는 능력과 그것이 정확하게 작동한다고 확신하는 것 사이에서 절충하려고 할 겁니다. 둘 다를 얻으려다 보면 우리의 이해력이 제한됩니다.
And our understanding is very limited, right? There's the whole notion of, you know, how many balls can you keep in the air at the time, or how many things can you keep in mind at a time? It's a limited number, and it's a very small number, right? So, we can only consider a few things and, when things are intertwined together, we lose the ability to take them in isolation.
우리의 이해력은 사실 제한적입니다. 우리가 공 몇 개를 저글링할 수 있나요? 한 번에 몇 가지 일을 기억할 수 있나요? 아주 적은 숫자에 불과하죠. 이렇게 우리는 한 번에 딱 몇 개만 고려할 수 있습니다. 생각할 것들이 서로 뒤섞여버리면 그것들을 각각 떼어놓고 다루지 못하게 됩니다.
So if every time I think I pull out a new part of the software I need to comprehend, and it's attached to another thing, I had to pull that other thing into my mind because I can't think about the one without the other. That's the nature of them being intertwined. So, every intertwining is adding this burden, and the burden is kind of combinatorial as to the number of things that we can consider. So, fundamentally, this complexity, and by complexity, I mean this braiding together of things, is going to limit our ability to understand our systems.
그래서 저는 소프트웨어에서 처음 보는 부분을 마주할 때마다 그걸 이해하는 과정을 거쳤습니다. 한 부분은 다른 부분과 연결됐는데, 서로가 없이는 해석이 불가능해서 둘 모두를 머릿속에 집어 넣어야 했습니다. 서로 얽힌 것들의 본성이 그렇죠. 이러한 얽힘은 기억력에 부담을 줍니다. 우리가 한 번에 고려할 수 있는 개수가 제한적이기 때문이죠. 바로 이 복잡성 때문에 우리는 시스템을 이해하는 데 한계를 느낍니다.

So how do we change our software? Apparently, I heard in a talk today, that Agile and Extreme Programming have shown that refactoring and tests allow us to make change with zero impact.
그렇다면 우리가 어떻게 소프트웨어를 수정할 수 있을까요? 오늘 제가 다른 강연을 들었는데요. 거기서는 애자일과 익스트림 프로그래밍이 좋다고 하더군요. 리팩터링과 테스트를 이용하면 코드 수정이 미치는 영향이나 부작용을 완전히 없앨 수 있다고요.
[Audience laughter]
[관객들의 웃음]
I never knew that. I still do not know that.
저는 그게 뭔지 몰랐고 여전히 모르겠습니다.
[Audience laughter]
[관객들의 웃음]
That's not actually a knowable thing. That's phooey.
그건 사실 알 수 있는 게 아니에요. 말이 안 됩니다.
[Audience laughter]
[관객들의 웃음]
Right? If you're going to change software, you're going to need to analyze what it does and make decisions about what it ought to do. You know, I mean, at least you're going to have to go and say, "What is the impact of this potential change?" Right? "And what parts of the software do I need to go to effect the change?"
소프트웨어를 수정하려면, 뭘 하는 소프트웨어인지 분석하고, 뭘 해야 하는지 결정해야 합니다. 최소한 ‘이 변화의 영향력은 어디까지지?’라는 질문을 던져야만 합니다. ‘그러면 수정 사항을 적용할 부분은 어디지?’라고도요.
You know, I don't care if you're using XP or Agile or anything else. You're not going to get around the fact that if you can't reason about your program, you can't make these decisions. But I do want to make clear here because a lot of people, as soon as they hear the words ‘reason about’, they're like, "Oh, my God! Are you saying that you have to be able to prove programs?" I am not. I don't believe in that. I don't think that's an objective. I'm just talking about informal reasoning, the same kind of reasoning we use every day to decide what we're going to do. We do not take out category theory and say, "Woo," you know. We actually can reason without it. Thank goodness.
XP든 애자일이든 상관없습니다. 프로그램을 추론할 수 없으면 이런 식의 결정도 할 수 없습니다. 여기서 한 가지 짚고 넘어갈 부분이 있습니다. 많은 분들이 ‘추론’이란 단어를 듣자마자 생각할 겁니다. “세상에 프로그램을 증명하라는 말인가요?” 아니요. 그런 말이 아닙니다. 추론 자체를 다루려는 이야기가 아닙니다. 그냥 일상적인 추론을 말하는 거예요. 우리가 매일 뭘 할지 결정할 때 하는 그 추론이요. 그럴 때 범주론을 적용하진 않잖아요. 그런 것 없이도 추론할 수 있어요. 참 감사한 일이죠.

So, what about the other side? Right? There are two things you do with the future of your software. One is, you add new capabilities. The other thing is you fix the ones you didn't get, you know, done so well.
이제 다른 면을 살펴보죠. 여러분이 미래에 소프트웨어에 할 일은 두 가지입니다. 하나는 새 기능을 추가하는 것이죠. 또 하나는 제대로 만들지 못했던 걸 고치는 일입니다.
And I like to ask this question: What's true of every bug found in the field?
이렇게 물어보죠. 실무에서 발생하는 모든 버그에 대하여 참인 명제는 무엇일까요?
[Audience reply: Someone wrote it?]
[관객의 답변: 누군가 작성했다?]
[Audience reply: It got written.]
[관객의 답변: 누군가 썼겠죠.]
It got written. Yes. What's a more interesting fact about it? It passed the type checker.
맞아요. 누군가 썼어요. 더 흥미로운 사실은요? 타입 체커를 통과했다는 것이죠.
[Audience laughter]
[관객들의 웃음]
What else did it do?
또 있을까요?
[Audience reply: (Indiscernible)]
[관객의 답변: (알아들을 수 없음)]
It passed all the tests. Okay. So now what do you do? Right? I think we're in this world I'd like to call guardrail programming. Right? It's really sad. We're like: I can make change because I have tests. Who does that? Who drives their car around banging against the guardrail saying, "Whoa! I'm glad I've got these guardrails because I'd never make it to the show on time."
테스트도 다 통과했죠. 좋아요. 그럼 이제 뭘 할까요? 저는 우리가 ‘가드레일 프로그래밍’ 시대에 살고 있다고 생각합니다. 슬프게도요. 이런 거예요. “테스트 덕분에 코드를 수정할 수 있어.” 그런데 이런 사람이 있나요? 일부러 가드레일에 차를 부딪히면서 “우와! 가드레일님 감사해요! 가드레일님이 아니었다면 제 시간에 못 왔을 거예요!”
[Audience laughter]
[관객들의 웃음]
Right? And - and do the guardrails help you get to where you want to go? Like, do guardrails guide you places? No. There are guardrails everywhere. They don't point your car in any particular direction. So again, we're going to need to be able to think about our program. It's going to be critical. All of our guardrails will have failed us. We're going to have this problem. We're going to need to be able to reason about our program. Say, "Well, you know what? I think," because maybe if it's not too complex, I'll be able to say, "I know, through ordinary logic, it couldn't be in this part of the program. It must be in that part, and let me go look there first," things like that.
가드레일이 여러분의 목적지로 가는 데 도움이 되나요? 길을 안내해주나요? 아니죠. 가드레일은 어디에나 있지만, 특정한 방향을 알려주진 않아요. 우리의 프로그램에 이 사실을 대입해보죠. 아주 중요합니다. 가드레일은 우리를 실패하게 합니다. 이런 문제를 생각해봅시다. 우리는 프로그램을 추론할 수 있어야 합니다. “제 생각에는...”이라고 말하기 보다는, “상식적으론 이 부분이 아니예요. 다른 부분일 텐데 제가 한 번 볼게요”라고 말해야 합니다. 너무 복잡하지만 않다면 말이죠.
Now, of course, everybody is going to start moaning, "But I have all this speed. I'm agile. I'm fast. You know, this easy stuff is making my life good because I have a lot of speed."
물론 사람들이 불평하기 시작할 겁니다. “저는 이미 민첩하고 빨라요. 이 방법이 제 삶을 풍요롭게 만들고 있다고요. 왜냐하면 저는 빠르니까요.”
What kind of runner can run as fast as they possibly can from the very start of a race?
하지만 여러분, 어떤 주자가 달리기 시작부터 최대한 빨리 달릴 수 있을까요?
[Audience reply: Sprinter]
[관객의 답변: 단거리 주자(스프린터)]
Right, only somebody who runs really short races, okay?
네. 아주 짧은 거리를 달리는 사람만 가능하죠. 그렇죠?
[Audience laughter]
[관객들의 웃음]
But of course, we are programmers, and we are smarter than runners, apparently, because we know how to fix that problem, right? We just fire the starting pistol every hundred yards and call it a new sprint.
하지만 우리는 달리기 선수보다 똑똑한 프로그래머니까 이 문제를 해결할 방법을 알고 있죠. 100미터마다 신호총을 쏘면서 그걸 새 스프린트라고 부르면 됩니다.
[Audience laughter and applause]
[관객들이 웃으며 박수침]
I don't know why they haven't figured that out, but -- right. It's my contention, based on experience, that if you ignore complexity, you will slow down. You will invariably slow down over the long haul.
왜 그들이 깨닫지 못하는지 저는 모르겠습니다. 제 경험상 복잡성을 무시하고 달리다보면 속도가 느려지더군요. 장기적으로 봐선 반드시 느려질 겁니다.
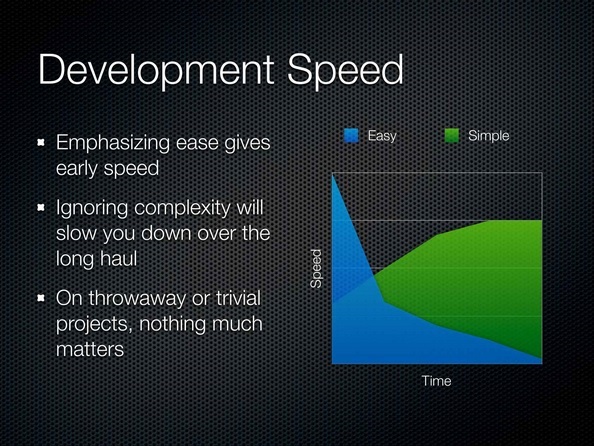
Of course, if you are doing something that's really short term, you don't need any of this. You could write it, you know, in ones and zeros. And this is my really scientific graph. You notice how none of the axis are -- there's no numbers on it because I just completely made it up.
물론 여러분이 정말 짧은 기간 동안 만들고 말거라면 지금 하는 이야기는 다 쓸모 없습니다. 그냥 만드세요. 0에서 1을 만드는 거죠. 여기 보시면 제가 만든 완전 과학적인 그래프가 있습니다. 어느 축에도 숫자가 없죠? 제가 방금 만든 엉터리 그래프라서 그래요.
[Audience laughter]
[관객들의 웃음]
It's an exponential graph, and what it shows is if you focus on ‘ease’ and ignore ‘simplicity’, so I'm not saying you can't try to do both. That would be great. But if you focus on ease, you will be able to go as fast as possible from the beginning of the race. But no matter what technology you use, or sprints or firing pistols, or whatever, the complexity will eventually kill you. It will kill you in a way that will make every sprint accomplish less. Most sprints be about completely redoing things you've already done. And the net effect is you're not moving forward in any significant way.
이건 지수 그래프입니다. 단순함을 무시하고 쉬움에만 초점을 맞추면 어떻게 되는지 보여줍니다. 두 마리 토끼를 다 잡지 말라고 말하는 게 아닙니다. 그건 훌륭한 일이죠. 그래프를 보면 여러분이 쉬움에만 집중한다면 초반에는 전력 질주할 수 있을 겁니다. 다만 어떤 기술을 쓰더라도, 스프린트나 신호총 혹은 다른 어떤 경우에도 결국엔 복잡성이 여러분을 괴롭힐 거예요. 매 스프린트마다 완성하지 못하게 할 거예요. 대다수 스프린트가 이미 했던 일의 재작업이 될 겁니다. 결국 여러분은 제자리 걸음만 하게 될 거예요.
Now if you start by focusing on simplicity, why can't you go as fast as possible right at the beginning? Right, because some tools that are simple are actually as easy to use as some tools that are not. Why can't you go as fast then?
반대로 단순함에만 집중했을 때 처음부터 전력으로 달리지 못하는 이유는 뭘까요? 안 그런 것도 있지만, 어떤 단순한 도구들은 쉽기도 하죠. 그런데 왜 빨리 못 달릴까요?
[Audience response: You have to think.]
[관객의 답변: 생각해야 하기 때문입니다.]
You have to think. You have to actually apply some simplicity work to the problem before you start, and that's going to give you this ramp up.
네. 생각해야 해요. 시작하기 전에 문제를 단순한 형태로 바라보는 일에 시간을 써야 해요. 그러면 그래프처럼 이렇게 올라갈 겁니다.

One of the problems I think we have is this conundrum that some things that are easy actually are complex. So let's look. There are a bunch of ‘construct’s that have complex ‘artifacts’ that are very succinctly described. Right? Some of the things that are really dangerous to use are like so simple to describe. They're incredibly familiar, right? If you're coming from object-orientation, you're familiar with a lot of complex things. They're very much available. Right?
또다른 문제로 이런 역설이 있습니다. ‘쉬운 것이 사실은 복잡하다’라는 경우입니다. 한 번 봅시다. 슬라이드에 복잡한 결과물(artifacts)을 생성하는 도구(constructs)의 특징을 적어 보았습니다. 그것들은 간단명료하게 설명할 수 있습니다. 어떤 위험한 도구(constructs)들은 정말 단순합니다. 또, 굉장히 친숙합니다. 객체지향 분야에서 오신 분이라면 상당수의 복잡한 객체에 익숙할 겁니다.
And they're easy to use. In fact, by all measures, conventional measures, you would look at them and say this is easy. Right? But we don't care about that. Right? Again, the user is not looking at our software, and they don't actually care very much about how good a time we had when we were writing it. Right? What they care about is what the program does, and if it works well, it will be related to whether or not the output of those constructs was simple. In other words, what complexity did they yield?
사용하기도 쉽죠. 일반적으로 ‘이 기계들은 사용하기 쉽다’고 말할 겁니다. 하지만 우리는 거기에 관심이 없습니다. 다시 말하지만, 사용자들은 우리의 소프트웨어를 들여다보지 않습니다. 우리가 소프트웨어를 만들 동안 얼마나 재밌었는지는 관심 밖이예요. 이 프로그램이 뭘 할 수 있는지, 잘 작동하는지만 봅니다. 이건 기계가 얼마나 단순한지와도 관련이 있습니다. 다른 말로 하면, 얼마나 복잡한 결과물을 만들 수 있냐는 거죠.
When there is complexity there, we're going to call that incidental complexity. Right? It wasn't part of what the user asked us to do. We chose a tool. It had some inherent complexity in it. It's incidental to the problem. I didn't put the definition in here, but incidental is Latin for ‘your fault’.
이 복잡함을 가리켜 우발적인(incidental) 복잡함이라고 부릅시다. 이 복잡함은 사용자들이 원한 게 아닙니다. 우리가 선택한 도구에 내재됐던 거예요. 문제에 대해서도 우발적입니다. 여기에 적진 않았지만 우발적(incidental)이란 라틴어로 ‘여러분의 잘못’이라는 뜻입니다.
[Audience laughter]
[관객들의 웃음]
And it is, and I think you really have to ask yourself, you know, are you programming with a loom? You know, you're having a great time. You're throwing that shuttle back and forth. And what's coming out the other side is this knotted, you know, mess. I mean it may look pretty, but you have this problem. Right? What is the problem? The problem is the ‘knitted castle’ problem. Right?
여러분은 자문하셔야 합니다. 베틀로 프로그램을 짠다고 해봅시다. 재미있겠죠. 북을 앞뒤로 움직이면, 반대편에서는 씨실과 날실이 서로 엮여 매듭을 만듭니다. 예쁠 수는 있겠지만 이제 문제가 생깁니다. 뭐가 문제일까요? ‘뜨개질로 만든 성’이라는 문제입니다.

Do you want a knitted castle? What benefits do we get from simplicity? We get ease of understanding, right? That's sort of definitional. I contend we get ease of change and easier debugging. Other benefits that come out of it that are sort of on a secondary level are increased flexibility. And when we talk more about modularity and breaking things apart, we'll see where that falls. Like the ability to change policies or move things around, right? As we make things simpler, we get more independence of decisions because they're not interleaved, so I can make a location decision. It's orthogonal from a performance decision.
뜨개질된 성을 원하시나요? 단순함의 이점은 무엇인가요? 단순하면 이해하기 쉽죠. 그게 단순함의 정의이기도 하니까요. 수정하기도 쉽고 디버깅도 쉬워집니다. 게다가 유연성도 높아집니다. 정책을 변경하거나 코드를 이곳저곳으로 옮기는 능력 말입니다. 모듈화와 격리에 대해서는 나중에 더 이야기하죠. 뭔가를 단순하게 만들면 그만큼 독립적으로 생각할 수 있습니다. 뒤섞여 있지 않으니 location decision할 수 있죠. location decision은 performance decision과 직교하는 개념입니다.
And I really do want to, you know, ask the question, agilest or whatever: Is having a test suite and refactoring tools going to make changing the knitted castle faster than changing the Lego castle? No way. Completely unrelated.
그리고 정말로 묻고 싶습니다. 애자일이건 뭐건 간에. 테스트 스위트랑 리팩터링 도구를 갖고 있으면 뜨개질로 만든 성을 빨리 고칠 수 있나요? 레고로 만든 성보다요? 아니요. 전혀 그렇지 않습니다.

Okay. So how do we make things easy? Presumably, you know, the objective here is not to just bemoan their software crisis, right? So what can we do to make things easier? So we'll look at those parts, those aspects of being ‘easy’ again. There's a ‘location’ aspect. Making something at hand, putting it in our toolkit, that's relatively simple. Right? We just install it. Maybe it's a little bit harder because we have to get somebody to say it's okay to use it.
그럼 어떻게 해야 더 쉬워질까요? 소프트웨어에 위기가 닥쳤다고 한탄하려는 게 아닙니다. 코드짜기를 더 쉽게 만들려면 어떻게 해야 할까요? ‘쉬움’의 여러 측면으로 돌아가 봅시다. 위치(가까움)에 대한 개념이 있었습니다. 가까운 도구상자에 넣어두면 더 쉽게 꺼내쓸 수 있죠. 설치만 하면 돼요. 물론 “이 소프트웨어를 쓰세요”라고 말하는 게 조금 어려울 수는 있겠지만요.
Then there's the aspect of ‘how do I make it familiar’, right? I may not have ever seen this before. That's a learning exercise. I've got to go get a book, go take a tutorial, have somebody explain it to me. Maybe try it out. Right? Both these things we're driving. We're driving. We install. We learn. It's totally in our hands.
익숙함이라는 개념도 있었죠. 어떻게 익숙해질 수 있을까요? 이번에 처음 보는 것도 있겠죠. 배우면 됩니다. 책을 구해서 읽고, 튜토리얼을 따라서 해보고, 누군가에게 설명을 부탁할 수도 있어요. 해보세요. 우리가 운전을 배울 때도 그랬잖아요. 설치하고, 배우세요. 그건 우리 손에 달렸어요.
Then we have this other part though, which is the mental capability part. And that's the part that's always hard to talk about, the mental capability part because, the fact is, we can learn more things. We actually can't get much smarter. We're not going to move; we're not going to move our brain closer to the complexity. We have to make things near by simplifying them.
다음으로 넘어가봅시다. 바로 정신 능력입니다. 이 정신 능력은 언급하기 어려운 주제입니다. 왜냐하면 우리가 더 많은 걸 배울 수는 있지만, 더 똑똑해질 수는 없기 때문입니다. 우리의 뇌가 복잡함에 가까이 갈 수는 없습니다. 그 대신 단순하게 만들어서 뇌 근처로 가져와야 합니다.
But the truth here is not that they're these super, bright people who can do these amazing things and everybody else is stuck because the juggling analogy is pretty close. Right? The average juggler can do three balls. The most amazing juggler in the world can do, like, 9 balls or 12 or something like that. They can't do 20 or 100. We're all very limited. Compared to the complexity we can create, we're all statistically at the same point in our ability to understand it, which is not very good. So, we're going to have to bring things towards us.
굉장히 똑똑한 사람들만 그렇게 할 수 있는 건 아닙니다. 정말로요. 저글링 비유를 떠올려보죠. 평범한 저글러는 공 세 개를 다룹니다. 세상에서 가장 뛰어난 저글러라도 한 번에 아홉에서 열두 개 사이의 공만 다룰 수 있어요. 스무 개나 백 개를 다루진 못합니다. 우리 모두에게 한계가 있어요. 우리가 만들어 내는 복잡한 것에 비해, 그걸 이해하는 능력은 통계적으로 비슷하게 나쁘다는 말입니다. 그러니 단순하게 만들어서 우리 쪽으로 가져와야 한다는 말입니다.
And because we can only juggle so many balls, you have to make a decision. How many of those balls do you want to be incidental complexity and how many do you want to be problem complexity? How many extra balls? Do you want to have somebody throwing you balls that you have to try to incorporate in here? Oh, use this tool. And you're like, whoa! You know, more stuff. Who wants to do that?
그리고 여러 공을 저글링할 때는 결정을 내려야 합니다. 우발적인 복잡함은 어떤 공들인가요? 문제 자체를 다루는 복잡함은 어떤 공들이어야 할까요? 남는 공은 몇 개죠? 다른 사람들이 공을 더 던져주면서 “이것도 같이 저글링해주세요”라고 하면 어떨까요? 이런저런 도구를 쓰면 된다고 하면서 말이죠. 그러면 “어이쿠!”하게 되겠죠? 이런 상황을 원하시나요?

All right, so let's look at a fact.
좋아요, 이제 진실을 말할 차례네요.
[Audience laughter]
[관객들의 웃음]
I've been on the other side of this complaint, and I like it. We can look at it really quickly only because it's not -- this analysis has nothing to do with the usage. This complexity analysis is just about the programmer experience. So parens are hard. Right? They're not at hand for most people who haven't otherwise used it.
저는 ‘괄호가 어렵다’는 말에 반대합니다. 저는 좋아하거든요. 눈에 잘 띄잖아요. 물론 사용량을 분석하거나 하진 않았지만요. 지금 말하려는 복잡성 분석은 오직 개발 경험에만 국한된 겁니다. 괄호가 어렵긴 하죠. 대다수 사람들은 괄호를 사용하지 않기 때문에 손에 익숙하지 않아요.
And what does that mean? It means that, like, they don't have an editor that knows how to do, you know, paren matching or move stuff around structurally, or they have one and they've never loaded the mode that makes that happen. Totally given, right? It's not at hand, nor is it familiar. I mean, everybody has seen parentheses, but they haven't seen them on that side of the method.
그래서 무슨 뜻이냐고요? 그 사람들은 괄호 매칭을 이해하는 코드 에디터를 사용해 본 적이 없어요. 코드를 구조적으로 바꿔주는 코드 에디터도요. 혹자는 사용하고는 있겠지만 해당 기능을 써본 적은 없을 거예요. 이미 기능이 있는데도요. 기능이 익숙하지 않으니까요. 괄호가 있으면 누구나 눈으로 볼 수 있죠. 하지만 메서드 앞에서 열리는 괄호는 본 적이 없을 거예요.
[Audience laughter]
[관객들의 웃음]
I mean [laughter] that is just crazy!
[웃으며] 진짜 웃기죠!
[Audience laughter]
[관객들의 웃음]
But, you know, I think this is your responsibility, right, to fix these two things, as a user, as a potential user. You've got to do this. But we could dig deeper. Let's look at the third thing. Did you actually give me something that was simple? Is a language built all out of parens simple? In the case I'm saying, right, is it free of interleaving and braiding? And the answer is no. Right?
하지만 아시다시피 이건 여러분이 적응해야 해요. 사용자로서, 혹은 사용자가 되기 위해서는 괄호에 익숙해져야 합니다. 하지만 더 파고듭시다. 세 번째 문제를 살펴보죠. 정말로 단순한 게 맞아요? 괄호로 둘러싸인 언어라면 무조건 단순한가요? 엮이거나 꼬이는 문제를 겪지 않나요? 아닙니다.
Common LISP and Scheme are not simple in this sense, in their use of parens, because the use of parentheses in those languages is overloaded. Parens wrap calls. They wrap grouping. They wrap data structures. And that overloading is a form of complexity by the definition, you know, I gave you. Right?
괄호를 사용하는 ‘커먼 리스프’ 혹은 ‘스킴’은 이런 의미에서는 단순하지 않습니다. 괄호를 너무 많이 사용하기 때문이죠. 호출할 때도 괄호. 그루핑할 때도 괄호. 자료구조도 괄호. 이렇게 괄호를 남용하면 복잡성이 생겨버립니다. 이미 말씀드렸듯이요.
And so, if you actually bothered to get your editor set up and learn that the parentheses goes on the other side of the verb, this was still a valid complaint. Now, of course, everybody was saying easy, and it's hard, it's complex in that we’re using these words really weakly. Right? But it was hard for a couple reasons you could solve, and it was not simple for a reason that was the fault of the language designer, which was that there was overloading there. And we can fix that. Right? We can just add another data structure.
이렇다 보니 에디터를 설정하고 괄호를 다루기 위해 커서를 이리저리 움직여야 하는 것은, 불평할 만하죠. 물론 사람들이 너무 대충 이건 쉽고, 혹은 어렵고, 저건 복잡하다고 말합니다. 하지만 그 어려움은 여러분이 해결할 수 있는 거예요. 그게 단순하지 않은 이유는 언어 설계자가 괄호를 남발하도록 설계를 잘못했기 때문이고요. 우리가 고칩시다. 데이터 구조를 추가하면 되잖아요.
It doesn't make LISP not LISP to have more data structures. Right? It's still a language defined in terms of its own data structures. But having more data structures in play means that we can get rid of this overloading in this case, which then makes it your fault again because the simplicity is back in the construct, and it's just a familiarity thing, which you can solve for yourself.
리스프에 자료구조를 추가해도 여전히 리스프입니다. 여전히 코드는 자체 자료구조로 정의되는 것이니까요. 하지만 추가한 자료구조 덕에 괄호 남용을 없앨 수 있습니다. 도구가 단순해졌으니 여기서부터는 우리의 잘못입니다. 하지만 이런 잘못에는 익숙하니까 우리 스스로 고칠 수 있죠.

Okay. This was an old dig at LISP programmers. I'm not totally sure what he was talking about. I believe it was a performance related thing. The LISPers, they consed up all this memory, and they did all this evaluation, and it was a pig. LISP programmers at that time were -- LISP programs at that time were complete pigs relative to the hardware. So, you know, they knew the value of all these constructs, right, this dynamic nature. These things are all great. They are valuable, but there was this performance cost.
네, LISP 프로그래머들에겐 오래된 명언이죠. 하지만 저는 앨런이 무슨 말을 하는지 잘 모르겠습니다. 아마 성능과 관련 있지 않을까 싶은데요. 왜냐하면 당시 LISP 프로그래머들은 모든 걸 메모리에 올려두고 실행했으니까요. 엄청나게 덩치가 컸죠. 당시 하드웨어에 비해서요. 그들은 동적인 특성을 활용한 도구 사용의 가치를 알고 있었습니다. 다 훌륭한 것들이죠. 가치가 있지만 성능이 문제였습니다.

I'd like to lift this whole phrase and apply it to all of us right now. As programmers, we are looking at all kinds of things, and I just see it. You know, read Hacker News or whatever. It's like, oh, look; this thing has this benefit. Oh, great. I'm going to do that. Oh, but this has this benefit. Oh, that's cool. Oh, that's awesome. You know, that's shorter. You never see in these discussions: was there a tradeoff? Is there any downside? You know, is there anything bad that comes along with this? Never. Nothing.
이 오랜 격언을 끄집어 내어 이 시대의 우리에게도 적용해봅시다. 우리 프로그래머들은 다양한 것들을 살펴봅니다. 해커 뉴스 같은 걸 읽고 그러죠. 그러다가 이렇게 말합니다. “이것 좀 봐. 이런 장점이 있네. 좋아. 써봐야겠어. 어, 저건 다른 장점이 있네. 훌륭해. 게다가 더 짧잖아.” 하지만 이렇게 묻진 않죠. “이런 장점을 얻으려고 희생한 건 뭐지? 단점은 없나? 나빠지는 점이 있을까?” 결코 묻지 않아요.
It's just like we look all for benefits. So as programmers now, I think we're looking all for benefits, and we're not looking carefully enough at the byproducts.
우리 모두는 장점만 찾아 다닙니다. 하지만 부작용을 면밀히 살펴보지는 않죠.
So, what's in your toolkit? I have, you know, I have these two columns. One says complexity and one says simplicity. The simplicity column just means simpler. It doesn't mean that the things over there are purely simple. Now I didn't label these things bad and good. I'm leaving your minds to do that.
여러분의 도구상자엔 무엇이 있죠? 표를 봅시다. 왼쪽 열은 복잡함, 오른쪽 열은 단순함입니다. 단순함 열은 상대적으로 단순하다는 뜻입니다. 절대적이 아니라요. 선악의 개념도 아닙니다. 그렇게 받아들여도 어쩔 수 없지만요.
[Audience laughter]
[관객들의 웃음]
So what things are complex and what are the simple replacements? I'm going to dig into the details on these, so I won't actually explain why they're complex, but I'm going to state and objects are complex, and values are simple and can replace them in many cases. I'm going to say methods are complex, and functions are simple. And namespaces are simple. The reason why methods are there are because often the space of methods, the class or whatever, is also a mini, very poor namespace.
복잡한 뭔가를 단순한 것으로 바꿀 수 있을까요? 이 내용으로 깊이 들어가보죠. 복잡한 것들이 왜 그런지 설명하지는 않을 겁니다. 상태와 객체는 복잡하고, 값은 단순합니다. 많은 경우 값으로 상태와 객체를 대신할 수 있습니다. 메서드는 복잡하고 함수는 단순합니다. 네임스페이스도 단순하죠. 메서드는 클래스 같은 것들에 들어 있는데, 네임스페이스가 빈약하기 짝이 없죠.
Vars are complex and variables are complex. Managed references are also complex, but they're simpler. Inheritance, switch statements, pattern matching are all complex, and polymorphism a la carte is simple. Now remember the meaning of simple. The meaning of simple means unentangled, not twisted together with something else. It doesn't mean I already know what it means. Simple does not mean I already know what it means.
변수는 복잡합니다. ref도 복잡하긴 하지만 변수보다는 단순합니다. 상속, 스위치문, 패턴 매칭은 복잡하고, 원할 때 찾아 쓰는 다형성은 단순합니다. 단순함이 뭐였죠? 섞여 있지 않은 거죠. 다른 것들과 엮이지 않았다는 말입니다. 우리가 이미 알고 있다는 뜻이 아니예요.
Okay. Syntax is complex. Data is simple. Imperative loops, fold even, which seems kind of higher level, still has some implications that tie two things together, whereas set functions are simpler. Actors are complex, and queues are simpler. ORM is complex, and declarative data manipulation is simpler. Even Eric said that in his talk. He said it really fast near the end. “Oh, yeah, and eventual consistency is really hard for programmers.”
자, 문법은 복잡하고 데이터는 단순합니다. 명령형 반복문이나 폴드도 복잡합니다. 폴드가 고차원처럼 보이긴 하지만, 두 개념을 묶는다는 의미를 암시하기 때문에 복잡함에 속합니다. 반대로 set 함수는 단순하죠. 액터는 복잡하고 큐는 조금 단순합니다. ORM은 복잡하고 선언형 데이터 조직이 좀더 단순합니다. 에릭조차 자기 강연에서 말하더군요. “끝으로 갈수록 정말 빨라요”라고요. 뭐, 프로그래머들에게 궁극적 일관성이 “진짜 어렵긴” 하죠.
[Audience laughter]
[관객들의 웃음]
Conditionals are complex in interesting ways, and rules can be simpler. And inconsistency is very complex. It's almost definitionally complex because consistent means to stand together, so inconsistent means to stand apart. That means taking a set of things that are standing apart and trying to think about them all at the same time. It's inherently complex to do that. And anybody who has tried to use a system that's eventually consistent knows that.
조건문은 흥미롭게도 복잡합니다. 규칙은 더 단순합니다. 비일관성은 매우 복잡합니다. 이건 사전적인 의미로도 복잡한데요. 일관성이란 함께 선다는 의미이고, 따라서 그 반대는 서로 떨어져 선다는 말이기 때문입니다. 따로 떨어진 둘을 한꺼번에 고려해야 한다는 이야기죠. 이건 선천적으로 복잡합니다. 궁극적 일관성이 있는 시스템을 사용해 본 사람이라면 누구나 이 사실을 이해할 겁니다.

Okay. So there's this really cool word called complect. I found it.
여기에 Complect(엮여 있는)라는 멋진 단어가 있습니다. 제가 찾아냈죠.
[Audience laughter]
[관객들의 웃음]
I love it. It means to interleave or entwine or braid. Okay? I want to start talking about what we do to our software that makes it bad. And I don't want to say braid or entwine because it doesn't really have the good/bad connotation that complect has. Complect is obviously bad. Right?
저는 이 단어가 좋습니다. Complect란 끼워 넣거나 휘감거나 땋는다는 뜻입니다. 이제부터는 우리의 소프트웨어를 나쁘게 만드는 것에 대해 말하려고 합니다. 휘감거나(entwine) 땋는다(braid)는 단어는 접어두기로 하죠. 중립적으로 들리기 때문이죠. 반면 Complect는 명백하게 나쁘잖아요. 그렇죠?
[Audience laughter]
[관객들의 웃음]
It happens to be an archaic word, but there are no rules that say you can't start using them again, so I'm going to use them for the rest of the talk. So what do you know about complect? It's bad. Don't do it. Right? This is where complexity comes from: complecting. It's very simple.
Complect는 고어입니다. 하지만 다시 사용하지 말라는 법은 없죠. 그러니 저도 남은 시간 동안 이 단어를 사용하겠습니다. 여러분은 Complect에 대해 뭘 알고 있죠? 안 좋은 것. 하지 말 것. 복잡성(Complexity)이란 말이 Complecting에서 왔죠. 간단하죠?
[Audience laughter]
[관객들의 웃음]
In particular, it's something that you want to avoid in the first place. Look at this diagram. Look at the first one. Look at the last one. Right? It's the same stuff in both those diagrams, the exact. It's the same strips. What happened? They got complected.
특히, complect는 우리 프로그래머들이 애초에 피하고 싶은 거잖아요. 자, 이 그림을 보세요. 첫 번째 그림을 먼저 보고 마지막 그림을 한번 봐보세요. 첫번째 그림과 마지막 그림은 똑같은 줄인데, 다른 점은 뭘까요, 꼬여 있다는 것뿐입니다. 즉, 본질적으로 같은 것인데, 꼬여 있을 뿐인 거죠.
[Audience laughter]
[관객들의 웃음]
And now it's hard to understand the bottom diagram from the top one, but it's the same stuff. You're doing this all the time. You can make a program a hundred different ways. Some of them, it's just hanging there. It's all straight. You look at it. You say, I see it's four lines, this program. Right? Then you could type in four lines in another language or with a different construct, and you end up with this knot, so we've got to take care of that.
위에서부터 아래로 갈수록 이해하기 어렵습니다. 똑같은 줄인데도요. 우리가 이런 일을 매일 하는 거예요. 사람마다 다양한 방식으로 프로그램을 만듭니다. 어떤 프로그램은 그냥 걸려 있어요. 저렇게 직선으로요. 그걸 보면 이렇게 말하겠죠. ‘여기 네 줄이 있네.’ 그러곤 네 줄에 다른 언어나 도구를 추가할 거예요. 그렇게 끝내면 매듭이 생기는 거죠. 언젠가 해결해야 하는 매듭이죠.

So complect actually means to braid together. And compose means to place together. And we know that, right? Everybody keeps telling us. What we want to do is make composable systems. We just want to place things together, which is great, and I think there's no disagreement. Right? Composing simple components, simple in that same respect, is the way we write robust software.
Complect는 두 개를 엮는다는 의미입니다. 반대로 Compose(합성하다)는 함께 놓는다는 의미고요. 아시죠? 다들 그렇게 말하잖아요. 합성 가능한 시스템을 만들고 싶다고요. 요소들을 같이 놓고 싶은 겁니다. 여기엔 아무도 이견이 없을 거예요. 관점이 같은 단순한 요소를 합성한다. 이것이 바로 강력한 소프트웨어를 만드는 방법이죠.

So it's simple, right? All we need to do is – (everybody knows this. I'm up here just telling you stuff you know.) We can make simple systems by making them modular, right? We're done. I'm like halfway through my talk. I don't even know if I'm going to finish. It's so simple. This is it. This is the key.
아주 간단하죠? (다들 아시는 내용이예요. 제가 대표로 말할 뿐이고요.) 시스템을 모듈화하기만 하면 됩니다. 그럼 끝나요. 이제 제 강연이 절반 정도 지났네요. 끝나기나 할지 모르겠네요. 어쨌든 아주 간단합니다. 이게 다예요. 핵심이 나왔죠?
No, it's obviously not the key. Who has seen components that have this kind of characteristic? I'll raise my hand twice because not enough people are raising their hands. It's ridiculous, right? What happens? You can write modular software with all kinds of interconnections between them. They may not call each other, but they're completely complected.
아니요. 이건 핵심이 아니예요. 이런 식으로 모듈화된 구성요소를 보신 분? 많이들 손을 안 드시니 저라도 두 손을 들어봤어요. 이상하잖아요? 모듈화된 소프트웨어를 작성할 수 있잖아요. 이런 저런 형태로 서로 연결하고요. 이런 경우 서로를 호출하지 않더라도 이 둘은 완벽히 엮여 버리죠.
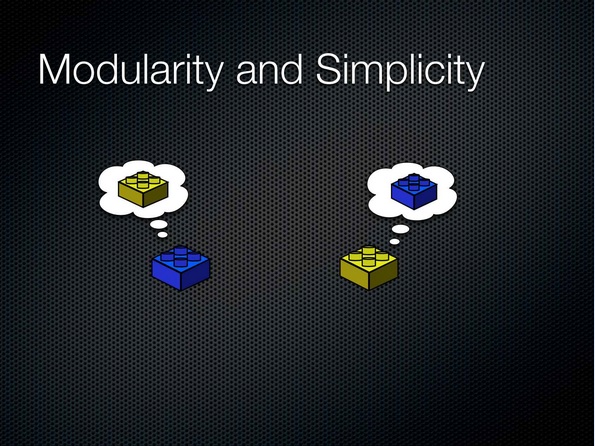
And we know how to solve this. It has nothing to do with the fact that there are two things. It has to do with what those two things are allowed to think about, if you want to really anthropomorphize.
우리는 해법을 알고 있습니다. 두 요소가 존재한다는 건 아무 의미가 없어요. 두 요소가 생각할 수 있다는 점이 의미 있습니다. 의인화를 해본다면 말이죠.

And what do we want to make things allowed to think about, and only these things? Some abstractions. I don't know if that's coming out that well. That's a dashed white version of the top of a Lego. That's all we want to limit things to because now the blue guy doesn't really know anything about the yellow guy, and the yellow guy doesn't really know anything about the blue guy, and they've both become simple.
이렇게 생각하게 만드는 방법이 무엇이죠? 추상화죠. (그림이 잘 보이실지 모르겠네요.) 흰색 점선으로 표시된 레고 윗부분 같은 거요. 바로 이것이 우리가 요소를 격리할 방법입니다. 파란 블럭은 노란 블럭을 전혀 모르고, 노란 블럭도 파란 블럭을 전혀 모르죠. 둘다 단순하게 남아 있어요.
So it's very important that you don't associate simplicity with partitioning and stratification. They don't imply it. They are enabled by it. If you make simple components, you can horizontally separate them, and you can vertically stratify them. Right? But you can also do that with complex things, and you're going to get no benefits.
이 단순함을 분할하기나 계층짓기와 연관시켜서는 절대 안 됩니다. 전혀 그런 뜻이 아니예요. 분할이나 계층짓기가 가능하게 만드는 것이 바로 단순함이기 때문입니다. 단순한 요소를 만들어서 수평으로 분할하거나 수직으로 계층지었다고 해보죠. 복잡한 요소에서도 이걸 할 수 있습니다. 아무 이익을 얻지 못할 뿐이죠.
And so I would encourage you to be particularly careful not to be fooled by code organization. There are tons of libraries that look, oh, look, there's different classes; there's separate classes. They call each other in sort of these nice ways, right? Then you get out in the field and you're like, oh, my God! This thing presumes that that thing never returns the number 17. What is that?
그러니 여러분이 코드 구조에 속지 마시기를 단단히 당부합니다. 수많은 라이브러리를 보면서, “이 클래스랑 저 클래스를 이렇게 나누었네. 서로는 이렇게 멋지게 호출하고.”라고 생각하겠죠? 그러곤 실무에서는 “아니 이런! 이건 절대로 17을 리턴하지 않을 것 같아요.”라고 말하겠죠. 이게 뭐예요.

Okay. I'm not going to get up here and tell you state is awesome. I like state. I'm not a functional whatever guy, whatever. I'm going to say instead: I did this, and it sucked. I did years and years: C++, you know, He-Man, stateful programming. It's really not fun. It's not good. It's never simple.
“저는 상태가 좋아요. 상태가 최고죠. 저는 함수형 프로그래머가 아니거든요” 이렇게 말하려고 여기 선 게 아니예요. 해봤는데 형편 없었다고 말하는 겁니다. 오랫동안 C++로 초능력자처럼 스테이트풀 프로그래밍을 해봤어요. 진짜 재미 없더군요. 단순하지도 않고요.
Having state in your program is never simple because it has a fundamental complecting that goes on in its artifacts. It complects value and time. You don't have the ability to get a value independent of time. And sometimes not an ability to get a value in any proper sense at all. But again, it's a great example. This is easy. It's totally familiar. It's at hand. It's in all the programming languages. This is so easy. This complexity is so easy.
프로그램에 상태를 유지하기란 결코 단순하지 않습니다. 상태의 결과물들이 근본적으로 서로 엮여가기(complect) 때문입니다. 시간과 값들을 엮죠(complect). 우리가 시간에 관계 없이 값을 얻을 수는 없습니다. 어떤 경우엔 아무리 애를 써도 값을 얻기가 불가능한 경우도 있고요. 하지만 이것 자체가 좋은 예입니다. 쉽고 익숙하니까요. 개념이 손에 잡히죠. 어쨌든 프로그래밍 언어니까요. 이런 종류의 복잡합은 익숙해서 쉽게 느껴지죠.
And you can't get rid of it. Everything – I’ll have modularity. That assignment statement is inside a method. Well, if every time you call that method with the same arguments, you can get a different result, guess what happened? That complexity just leaked right out of there. It doesn't matter that you can't see the variable. If the thing that's wrapping it is stateful and the thing that's wrapping that is still stateful, in other words by stateful I mean every time you ask it the same question you get a different answer, you have this complexity and it's like poison.
이런 복잡함은 없앨 수도 없어요. 모든 것이 이미 모듈일 테니까요. 메서드 안에 어떤 대입문이 있겠죠. 이 메서드에 똑같은 인자를 전달해도 결과는 달라지고요. 왜 이러죠? 바로 여기서 복잡함이 느껴집니다. 우리가 변수를 볼 수 없다는 건 아무 문제가 안 돼요. 상태를 유지해야 한다면, 그래서 똑같은 질문을 던져도 매번 대답이 다르다면 그게 바로 독성과 같은 복잡함이라는 말이예요.
It's like dropping some dark liquid into a vase. It's just going to end up all over the place. The only time you can really, you know, get rid of it is when you put it inside something that's able to present a functional interface on the outside, a true functional interface: same input, same output. You can't mitigate it through the ordinary code organization things.
물병에 검은색 독약을 떨어뜨리듯이요. 조금씩 흩어지다 마침내 전부 다 퍼져버리겠죠. 이런 독성을 제거할 유일한 방법은 메서드 대신 바깥에 있는 함수형 인터페이스 안에 넣는 겁니다. 진정한 함수형 인터페이스 말이예요. 입력이 같으면 출력이 항상 같은. 코드 구조를 바꾸는 정도로는 개선할 수 없습니다.
And note in particular, I didn't talk about concurrency here. This is not about concurrency. This has nothing to do with concurrency. It's about your ability to understand your program.
이제부터 특별히 주의할 점은, 동시성 이야기를 하려는 게 아니라는 겁니다. 동시성에 대한 이야기가 아니예요. 동시성과는 아무 관련이 없습니다. 오직, 우리가 만든 프로그램을 우리가 이해하는 능력에 대한 이야기입니다.
Your program was out there. It's single threaded. It didn't work. All the tests passed. It made it through the type checker. Figure out what happened. If it's full of variables, where are you going to need to try to do? Recreate the state that was happening at the client when it went bad. Is that going to be easy? No!
자, 우리가 만든 프로그램이 저기 있습니다. 싱글 스레드로 작동해요. 작동은 안 하네요. 테스트는 통과했고, 타입 검사도 통과 했는데도요. 무슨 일일까요? 이 프로그램에 변수들이 가득하다면 어디부터 확인해봐야 할까요? 문제가 발생한 컴퓨터에서 상태를 재현해봅시다. 근데 그게 쉬운 일일까요? 아니죠.

But we fix this, right? Your language, your new, shiny language has something called var, or maybe it has refs or references. None of these constructs make state simple. That's the first, primary thing. I don't want to say that even of Clojure's constructs. They do not make state simple in the case I'm talking about, in the nature of simple I'm talking about.
하지만 고쳐야만 해요. 새롭고 반짝거리는 여러분의 언어로요. var라든지 refs 같은 게 있다고 안심해선 안 됩니다. 이러한 도구들이 상태를 단순화할 수는 없습니다. 이것이 첫 번째로 중요한 점입니다. 클로저라 하더라도요. 클로저의 도구들도 상태에서 단순함의 본질을 끄집어 낼 수 없어요.
But they're not the same. They all do warn you when you have state, and that's great. Most people who are using a language where mutability is not the default and you have to go out of your way to get it, finds that the programs you end up writing have dramatically, like orders of magnitude, less state than they would otherwise because they never needed all the other state in the first place. So that's really great.
var나 ref가 할 수 있는 일도 있죠. 상태를 만들려고 할 때 경고해주거든요. 변이성을 내장하지 않은 언어로 개발하다보면, (제발 이렇게 개발하세요.) 프로그램의 크기가 현저히 줄어든다는 사실을 깨달을 겁니다. 상태도 줄어들고요. 왜냐하면 애초에 필요하지 않았던 것들이거든요. 정말 멋지죠.
But I will call out Clojure and Haskell's references as being particularly superior in dealing with this because they compose values and time. There are actually little constructs that do two things. They have some abstraction over time and the ability to extract a value. That's really important because that's your path back to simplicity. If I have a way to get out of this thing and get a value out, I can continue with my program. If I have to pass that variable to somebody else or a reference to something that's going to find the variable every time through the varying thing, I'm poisoning the rest of my system. So look at the var in your language and ask if it does the same thing.
특별히 클로저나 하스켈의 참조(reference)를 살펴보죠. 참조는 값과 시간을 합성한 개념이기 때문에 상태를 다루는 능력이 특히나 탁월합니다. 아주 작은 두 도구가 각각의 역할을 맡고 있죠. 시간이 가면서 추상화가 발생하고, 값을 꺼내올 수 있어요. 이게 정말 중요합니다. 단순함으로 가는 길이 여기 있거든요. 복잡함을 벗어나 값을 얻어낼 수 있다면 프로그램을 계속 만들 수 있잖아요. 값을 얻고 싶을 때마다 변수를 어디로 전달하거나 참조를 찾아 여기저기로 헤메야 한다면, 그건 시스템을 오염시키고 있다는 증거입니다. 그러니 여러분이 사용하는 언어에서 var가 이런 식으로 작동하는지 살펴보세요.

All right, let's see why things are complex. State, we already talked about. It complects everything it touches. Objects complect state, identity, and value. They mix these three things up in a way that you cannot extricate the parts.
좋아요. 이제 요소들이 왜 복잡해지는지 알아보죠. 상태는 이미 살펴봤죠. 상태는, 건드리는 족족 다 엮어 버립니다. 객체는 상태와 식별자, 값을 엮어 버리죠. 그러다보니 우리가 각 요소들을 분리하지 못하는 거예요.
Methods complect function and state, ordinarily, right? In addition, in some languages, they complect namespaces. Derive from two things in Java and have the same name method, and [hand gesture with sounds like explosion]. It doesn't work.
메서드는 보통, 함수와 상태를 엮습니다. 가끔 어떤 언어에서는 네임스페이스까지도 엮고요. 자바에 이름이 같은 두 메서드가 있다고 상상해보세요. (엉망이 되겠죠.) 제대로 작동할 수 없습니다.
Syntax, interestingly, complects meaning and order often in a very unidirectional way. Professor Sussman made the great point about data versus syntax, and it's super true. I don't care how many you really love the syntax of your favorite language. It's inferior to data in every way.
문법은 단방향으로 의미와 순서를 엮습니다. 흥미롭죠. 서스만 교수가 데이터 대 문법이라는 주제를 훌륭하게 짚었습니다. 정말 그래요. 여러분이 어떤 언어의 문법을 좋아하든 그건 상관 없습니다. 문법은 모든 면에서 데이터보다 열등합니다.
Inheritance complects types. These two types are complected. That's what it means: inheritance, complecting. It's definitional.
상속은 타입을 엮습니다. 두 타입이 엮여요. 그게 상속이잖아요. 사전적으로 상속은 엮는다는 뜻이니까 당연하죠.
Switching and matching, they complect multiple pairs of who's going to do something and what happens, and they do it all in one place in a closed way. That's very bad.
스위치와 매칭은 이럴 땐 이렇게 하고 저럴 땐 저렇게 하는 여러 조각을 한 데 모아 엮습니다. 아주 나쁘죠.
Vars and variables, again, complect value and time, often in an inextricable way, so you can't obtain a value. We saw a picture during a keynote yesterday of this amazing memory where you could de-reference an address and get an object out. I want to get one of those computers. Have you ever used one of those computers? I can't get one. I called Apple, and they were like, pff, no.
재등장한 변수 역시 값과 시간을 아주 밀접하게 엮습니다. 그래서 값을 얻지 못하게 만들죠. 어제 어떤 발표에서 놀라운 메모리 사진을 보셨죠. 메모리 주소를 역참조하여 객체를 꺼낼 수 있었습니다. 이런 컴퓨터 하나 갖고 싶더군요. 이런 컴퓨터 사용해 보신 분? 저는 구하지 못했습니다. 애플에 전화 했더니 황당해하며 없다더군요.
The only thing you can ever get out of a memory address is a word, a scalar, the thing that was all derided. Recovering a composite object from an address is not something computers do, none of the ones that we have. So variables have the same problem. You cannot recover a composite mutable thing with one de-reference.
메모리 주소에서 얻을 수 있는 건 오직 단어나 스칼라 뿐입니다. 무시당하던 것들이죠. 복합 객체를 메모리 주소에서 불러내는 건 컴퓨터가 하는 일이 아닙니다. 우리가 가진 컴퓨터 중에 그런 건 없어요. 이렇게 변수에도 문제가 있습니다. 한 번의 역참조로 복합적인 가변 항목을 불러올 수 없습니다.
Loops and fold: loops are pretty obviously complecting what you're doing and how to do it. Fold is a little bit more subtle because it seems like this nice, somebody else is taking care of it. But it does have this implication about the order of things, this left to right bit.
루프와 폴드. 루프는 여러분의 일과 일을 처리하는 방법에 명백하게 엮여 있습니다. 폴드는 조금 미묘한데요. 다른 곳으로 관심사를 던져둘 수 있기 때문입니다. 그럴싸하죠. 하지만 잘 생각해 보면 일의 순서가 존재한다는 이야기입니다. 왼쪽에서 오른쪽으로 순서대로 가는 거죠.
Actors complect what's going to be done and who is going to do it.
액터는 어떤 결과를 얻을지, 누가 그 일을 할지와 엮여 있습니다.
[Audience laughter]
[관객들의 웃음]
Now Professor Sussman said all these talks have acronyms, and I couldn't actually modify my slides in time, so object relational mapping has oh, my God complecting going on. You can't even begin to talk about how bad it is, right?
서스만 교수가 제 강의에 줄임말이 너무 많다고 하셨어요. 하지만 고칠 시간이 없더군요. 그래서 ORM은 그냥, OMG(오마이갓) 엮이고 있어라고 적었습니다. 이게 얼마나 나쁜지는 말할 필요도 없어요.
And, you know, if you're going to do, like, duals, what's the dual of value? Is it co-value? What's a co-value? It's an inconsistent thing. Who wants that?
플라톤의 이원론을 떠올려보세요. 값(value)에 대립하는 것은 뭔가요? 공-값(co-value)일까요? 그럼 공-값은 뭐죠? 그건 일관적이지 않은 것입니다. 이런 건 아무도 원하지 않겠죠?
Conditionals, I think, are interesting. This is sort of more cutting-edge area. We have a bunch of sort of rules about what our programs are supposed to do. It's strewn all throughout the program. Can we fix that, because that's complected with the structure of the program and the organization of the program?
조건문은 흥미롭긴 해요. 이건 중립에 가깝긴 합니다. 프로그램을 만들 땐 이러저러해야 한다는 규칙들이 많잖아요. 이런 규칙들이 프로그램 전체에 퍼져 있죠. 고칠 수 있을까요? 프로그램의 구조와 조직이 엮여 있는데 말이죠.

All right, so if you take away two things from this talk, one would be the difference between the words simple and easy. The other, I would hope, would be the fact that we can create precisely the same programs we're creating right now with these tools of complexity with dramatically drastically simpler tools. I did C++ for a long time. I did Java. I did C#. I know how to make big systems in those languages, and I completely believe you do not need all that complexity. You can write as sophisticated a system with dramatically simpler tools, which means you're going to be focusing on the system, what it's supposed to do, instead of all the gook that falls out of the constructs you're using.
좋습니다. 이 강연에서 챙겨갈 것 두 가지 중 하나는 단순함과 쉬움의 차이겠고요. 다른 하나는 단순하게 만들어주는 도구(이하 단순성 도구)로도 프로그램을 만들 수 있다는 사실입니다. 복잡함을 증가시키는 도구(이하 복잡성 도구)들로 만들던 것과 똑같은 프로그램을요. 저는 C++를 오래 사용했고 자바도 다뤘습니다. C#도요. 이런 복잡성 언어들로 큰 시스템을 만드는 방법을 알고 있죠. 하지만 여러분도 그렇게 하실 필요는 없습니다. 아주 복잡한 시스템이라도 단순성 도구로 충분하거든요. 다시 말해 여러분은 이제부터 시스템과 시스템의 목표에만 집중하면 됩니다. 더이상 도구를 사용하면서 생겨나는 찌꺼기들이 없을 테니까요.
So I'd love to say the first step in getting a simpler life is to just choose simpler stuff. Right? So if you want values, usually you can get it. Most languages have something like values. Final or val, you know, let's you, like, declare something as being immutable. You do want to find some persistent collections because the harder thing in a lot of languages is getting aggregates that are values. You've got to find a good library for that or use a language where there's the default.
이렇게 말할게요. 더 단순한 삶으로 가는 첫 걸음은 단순한 도구를 선택하는 것입니다. 여러분이 값을 얻고 싶다면 그냥 얻으면 되요. 대다수 언어에는 값 같은 게 있긴 하죠. Final이나 val 처럼 불변으로 선언하게 해주는 거요. 영속 컬렉션을 얻고 싶을 수도 있겠죠. 많은 언어에서 뭉쳐 있는 값들을 가져오기가 더 어렵기 때문인데요. 그래서 보통 그걸 지원하는 언어나 라이브러리를 사용하잖아요.
[Audience laughter]
[관객들의 웃음]
Functions, most languages have them. Thank goodness. If you don't know what they are, they're like stateless methods.
함수는 모든 언어에 있습니다. 감사한 일이죠. 함수가 뭔지 모르신다면, 상태 없는 메서드 같은 거예요.
[Audience laughter]
[관객들의 웃음]
Namespaces is something you really need the language to do for you and, unfortunately, it's not done very well in a lot of places.
네임스페이스는 정말로 언어에 필요합니다만, 안타깝게도 제대로 사용되는 경우가 별로 없습니다.
Data: Please! We're programmers. We're supposedly write data processing programs. There are always programs that don't have any data in them. They have all these constructs we put around it and globbed on top of data.
데이터: 제발! 우리는 프로그래머입니다. 우리는 데이터를 처리하는 프로그램을 만드는 사람들입니다. 데이터 없이 뭔가를 하는 프로그램들이 널려 있으니까요. 이 프로그램들은 여러 자료구조들을 통해 데이터로부터 뭔가를 추출해 냅니다.
Data is actually really simple. There are not a tremendous number of variations in the essential nature of data. There are maps. There are sets. There are linear, sequential things. There are not a lot of other conceptual categories of data. We create hundreds of thousands of variations that have nothing to do with the essence of this stuff and make it hard to write programs that manipulate the essence of the stuff. We should just manipulate the essence of the stuff. It's not hard. It's simpler.
데이터는 진짜 정말로 단순합니다. 데이터는 본질상 획기적으로 변할 수가 없어요. 맵, 집합 모두 직선적이고 순차적인 것들이죠. 개념적으로 다른 형태의 데이터는 별로 없습니다. 우리는 시스템과 상관 없는 수십만 가지의 변형을 만들어요. 그래서 본질을 다루는 프로그램을 만들기가 더욱 어려워지는데요. 그러지말고 그냥 본질만 다루자고요. 어렵지 않아요. 더 간단합니다.
Also, the same thing for communications. Are we all not glad we don't use the Unix method of communicating on the Web? Right? Any arbitrary command string can be the argument list for your program, and any arbitrary set of characters can come out the other end. Let's all write parsers.
통신도 마찬가지입니다. 웹 통신을 하려고 유닉스 메서드를 사용하지 않으니까 다행이잖아요? 명령어 전달인자도 복잡하고 출력도 제멋대로죠. 자, 파서를 작성합시다!
[Audience laughter]
[관객들의 웃음]
No, I mean it's a problem. It's a source of complexity. So we can get rid of that. Just use data.
이런 게 정말 문제입니다. 복잡함이 여기서 비롯되죠. 우리가 없앨 수 있습니다. 데이터를 사용하기만 하면요.
The biggest thing, I think, the most desirable thing, the most esoteric, this is tough to get, but boy when you have it your life is completely, totally different thing is polymorphism a la carte. Clojure protocols and Haskell-type classes and constructs like that. Give you the ability to independently say I have data structures, I have definitions of sets of functions, and I can connect them together, and those are three independent operations. In other words, the genericity is not tied to anything in particular. It's available a la carte. I don't know of a lot of library solutions for languages that don't have it.
정말로 중요한 건 이거예요. 비밀리에 전해오는, 얻기는 어렵지만 너무나 갖고 싶은 것. 갖기만 한다면 삶이 완전히 달라질 수 있는 건 다형성입니다. 클로저 프로토콜과 하스켈 타입 클래스 같은 것들요. 이 도구 덕에 우리는 이렇게 선언할 수 있습니다. 여기 데이터 구조가 있고, 저기엔 함수 집합을 정의해뒀고, 나는 이 둘을 연결할 수 있지. 이 셋은 모두 독립적인 작업이죠. 다시 말해 일반성은 다른 것에 얽메이지 않습니다. 각각을 취사선택할 수 있어요. 이런 기능이 없는 언어 라이브러리를 본 적이 없습니다.
I already talked about manage references and how to get them. Maybe you can use closures from different Java languages.
매니지드 참조는 이미 이야기했고요. 파생 자바 언어에 있는 클로저로 할 수 있겠죠.
Set functions, you can get from libraries. Queues, you can get from libraries. You don't need special communication language.
Set 함수. 라이브러리에 있습니다. 큐도 그렇고요. 이 둘은 특별한 언어가 필요 없죠.
You can get declarative data manipulation by using SQL or learning SQL, finally. Or something like LINQ or something like Datalog.
선언형 데이터 조작. SQL을 배우거나 사용하면 됩니다. LINQ나 Datalog 같은 것도 있고요.
I think these last couple of things are harder. We don't have a lot of ways to do this well integrated with our languages, I think, currently. LINQ is an effort to do that.
마지막 몇 가지가 좀 어려운 것들이죠. 언어랑 잘 통합할 방법이 아직은 많지 않습니다. LINQ가 그런 노력의 일환이고요.
Rules, declarative rule systems, instead of embedding a bunch of conditionals in our raw language at every point of decision, it's nice to sort of gather that stuff and put it over someplace else. You can get rule systems in libraries, or you can use languages like Prolog. If you want consistency, you need to use transactions, and you need to use values. There are reasons why you might have to get off of this list, but, boy, there's no reason why you shouldn't start with it.
규칙(Rule). 선언형 규칙 시스템. 의사 결정이 필요한 지점마다 조건문을 추가하지 마세요. 이런 걸 모아서 어디 다른 데에 두시기 바랍니다. 규칙 시스템은 라이브러리에 있거나 프롤로그 같은 언어가 지원해주기도 해요. 일관성. 트랜잭션이나 값을 사용해야 합니다. 이 표를 넘어설 수는 있겠지만, 일단 이 표에서부터 시작해야만 합니다.

Okay. There's a source of complexity that's really difficult to deal with, and not your fault. I call it environmental complexity. Our programs end up running on machines next to other programs, next to other parts of themselves, and they contend; they contend for stuff: memory, CPU cycles, and things like that.
네. 여러분의 잘못은 아니지만 다루기 어려운 복잡성의 원천이 있습니다. 저는 이걸 환경 복잡성이라고 부릅니다. 우리가 만든 프로그램은 어떤 기계에서 다른 프로그램들과 나란히 작동합니다. 혹은 그 프로그램들의 일부가 되기도 하고요. 그러면서 메모리나 CPU 사이클 같은 컴퓨팅 자원을 차지하려고 경쟁합니다.
Everybody is contending for it. This is an inherent complexity. Inherent is Latin for not your fault. In the implementation space and, no, this is not part of the problem, but it is part of implementation. You can't go back to the customer and say the thing you wanted is not good because I have GC problems. But the GC problems and stuff like that, they come into play.
모든 프로그램이 그렇게 경쟁해요. 복잡성을 내포(inherent)한 거죠. 내포(Inherent)란 라틴어로 “네 잘못이 아니야”라는 뜻이잖아요. 환경 자체가 그렇다는 말이예요. 이게 문제라고 말하는 게 아니라, 환경이 그렇다는 말입니다. 소비자들한테 가서 “가비지컬렉션에 문제가 있어요”라고 할 수는 없잖아요. 그렇지만 가비지컬렉션 같은 것들이 엄연히 존재하죠.
There are not a lot of great solutions. You can do segmentation. You can say this is your memory, this is your memory, this is your memory, this is your CPU and your CPU. But there's tremendous waste in that, right, because you pre-allocate. You don't use everything. You don't have sort of dynamic nature.
해결책이 많지는 않아요. 세그멘테이션을 해볼까요? 이건 네 메모리. 이건 내 메모리. 그리고 이건 네 CPU. 이것도 네 CPU. 뭔가 엄청 낭비 같지 않나요? 왜냐하면 이미 할당해두었으니까요. 우리가 모든 자원을 다 쓰는 건 아니잖아요. 그때그때 유연하게 쓸 수 없습니다.
But the problem I think we're facing, and it's not one for which I have a solution at the moment, is that the policies around this stuff don't compose. If everybody says, "I'll just size my thread pool to be the number of," you know, of course. How many times can you do that in one program? Not a lot and have it still work out.
하지만 지금 당면한 문제는 이런 정책들이 모여 있지 않다는 것입니다. 저한테 당장 해결책이 있진 않지만요. 모두가 이렇게 말한다고 해보죠. “나는 스레드 풀을 이만큼 정할거야” 이런 게 프로그램 하나에 몇 번이나 나타나겠어요? 많지 않아도 잘 작동할 거예요.
So, unfortunately, a lot of things like that, splitting that stuff up and making it an individual decision, is not actually making things simpler. It's making things complex because that's a decision that needs to be made by someone who has better information. And I don't think we have a lot of good sources for organizing those decisions in single places in our systems.
하지만 이런 식으로 일을 분리해서 독립적인 결정으로 만들었다고 해서, 실제로 일이 더 단순해진 건 아닙니다. 실은 일이 더 복잡해져요. 왜냐하면 더 나은 정보를 가진 사람이 결정할 수 있어야 하기 때문이죠. 게다가 이런 결정들을 모아둘 만한 적절한 위치가 별로 없기도 하고요.

This is a hugely long quote. Basically, it says programming is not about typing, like this [gestures of typing on a keyboard]. It's about thinking.
엄청 긴 인용문이 등장했네요. 이건 기본적으로 프로그래밍은 이처럼 [키보드를 치는 듯 하며] 타이핑하는 일이 아니라는 말입니다. 생각하는 일이죠.

So the next phase here--I've got to move a little bit quicker--is how do we design simple things of our own? So the first part of making things simple is just to choose constructs that have simple artifacts. But we have to write our own constructs sometimes, so how do we abstract for simplicity? An abstract, again, here's an actual definition, not made up one. It means to draw something away. And, in particular, it means to draw away from the physical nature of something.
이제 이야기를 좀더 발전시켜보죠. (좀더 빨리 진행할게요.) 단순함을 어떻게 설계할 수 있을까요? 단순하게 만드는 첫 번째 열쇠는 단순한 결과물을 만드는 도구를 선택하라는 겁니다. 가끔은 도구 자체를 만들어야 하는 경우도 있습니다. 이럴 땐 어떻게 단순함을 위한 추상이 가능할까요? 추상이란 단어의 정의는 하나가 아니라는 암시를 줍니다. 무언가를 추출한다는 뜻이잖아요. 물리적인 성질에서 빼내어 떨어뜨려두는 거죠.
I do want to distinguish this from, that sometimes people use this term really grossly to just mean hiding stuff. That is not what abstraction is, and that's not going to help you in this space.
이건 숨기기(hiding)와 구별해야 합니다. 어떤 사람들은 숨기기 위해 추상이란 단어를 오용해요. 하지만 그건 추상화가 아니죠. 그렇게 사용하는 게 이 시점에 여러분에게 도움이 되지도 않고요.
There are two -- you know, I can't totally explain how this is done. It's really the job of designing, but one approach you can take is just to do who, what, when, where, why, and how. If you just go through those things and sort of look at everything you're deciding to do and say, "What is the who aspect of this? What is the what aspect of it?" This can help you take stuff apart.
제가 추상을 완벽하게 설명할 수는 없습니다. 사실 설계 작업인 셈인데요. 첫째로는 육하원칙을 적용해 볼 수 있겠습니다. 누가, 언제, 무엇을 어디서, 어떻게, 왜라는 질문에 답해 보세요. 이런 방식으로 모든 것을 바라보고 결정하세요. "여기서 '누가'에 해당하는 것은? '무엇'에 해당하는 것은?" 이러한 질문을 던져보세요. 대상을 분해하는데 도움이 될겁니다.
The other thing is to maintain this approach that says, "I don't know; I don't want to know." I once said that so often during a C++ course I was teaching that one of the students made me a shirt. It was a Booch diagram because we didn't have whatever it is now, the unified one. And every line just said that. That's what you want to do. You really just don't want to know.
다른 방법으로는 “모르겠고, 알고 싶지도 않아.” 같은 태도를 취하는 겁니다. 제가 C++ 수업을 할 때 자주 그렇게 말했는데요. 한 학생이 저한테 티셔츠를 만들어 준 적이 있습니다. 당시에는 UML이 없어서, 부치 다이어그램을 그려두었더군요. 모든 선마다 “모르겠고, 알고 싶지도 않아”라고 적혀 있었어요. 이런 태도를 취하세요.

All right, so what is what? ‘What’ is the operations. What is what we want to accomplish. We're going to form abstractions by taking functions and, more particularly, sets of functions and giving them names. In particular – and you're going to use whatever your language lets you use. If you only have interfaces, you'll use that. If you have protocols or type classes, you'll use those. All those things are in the category of the things you use to make sets of functions that are going to be abstractions. And they're really sets of specifications of functions.
자, ‘무엇’부터 시작해봅시다. ‘무엇’이란 명령어입니다. ‘무엇’이란 우리가 성취하려는 것입니다. 함수로 추상화를 구현할 겁니다. 함수들에 이름을 붙여가면서요. 여러분이 사용하는 언어를 그냥 사용하시면 됩니다. 언어에 인터페이스만 존재한다면 그걸 쓰세요. 프로토콜이나 타입 클래스가 있다면 그걸 쓰면 되고요. 이런 것들은 도구입니다. 추상화를 구현할 함수들을 만드는 도구죠. 함수 규격 모음이 되기도 하고요.
The point I'd like to get across today is just that they should be really small, much smaller than what we typically see. Java interfaces are huge, and the reason why they are huge is because Java doesn't have union types, so it's inconvenient to say this function takes, you know, something that does this and that and that. You have to make a this and that and that interface, so we see these giant interfaces. And the thing with those giant interfaces is that it's a lot harder to break up those programs, so you're going to represent them with your polymorphism constructs.
요점은, 함수들이 정말로 아주 작아야한다는 겁니다. 우리가 보던 것들보다 훨씬 더요. 자바 인터페이스는 거대하죠. 유니온 타입이 없기 때문입니다. 그래서 이 함수가 이것과 저것, 또다른 저것을 사용한다는 식으로 불편하게 말해야 하죠. 그러려면 이 인터페이스와 저 인터페이스를 만들어야 하고, 그러다보면 덩치 큰 인터페이스가 만들어집니다. 이렇게 커다란 인터페이스는 작게 분해하기가 훨씬 어렵고요. 그러다보니 다형성 구조로 표현하게 되죠.
They are specifications, right? They're not actually the implementations. They should only use values and other abstractions in their definitions. So you're going to define interfaces or whatever, type classes, that only take interfaces and type classes or values and return them.
이것들은 모두 규격일 뿐입니다. 실제 구현은 없어요. 값과 추상화에 대한 정의만 들어 있죠. 그러니 인터페이스든 타입 클래스든 정의하고 나면, 인터페이스나 타입 클래스, 값을 반환할 뿐인 거죠.
And the biggest problem you have when you're doing this part of design is if you complect this with ‘how’. You can complect it with ‘how’ by jamming them together and saying here is just a concrete function instead of having an interface, or here's a concrete class instead of having an interface. You can also complect it with how more subtly by having some implication of the semantics of the function dictate how it is done. Fold is an example of that.
여기서 큰 문제가 생기는데요. 설계에 ‘어떻게’가 엮인다는(complect) 겁니다. 앞서 만든 설계에 ‘어떻게’를 욱여넣고는, ‘인터페이스 대신 구현체가 여기 있어’ 혹은 ‘인터페이스 대신 구체 클래스가 여기 있어’ 라고 말할테죠. 좀더 교묘한 방식으로는, 함수가 어떻게 작동해야하는지를 넌지시 암시하는 식으로 엮을 수도 있습니다. Fold 함수가 그 예죠.
Strictly separating what from how is the key to making how somebody else's problem. If you've done this really well, you can pawn off the work of how on somebody else. You can say database engine, you figure out how to do this thing or, logic engine, you figure out how to search for this. I don't need to know.
‘무엇’과 ‘어떻게’를 구분하는 것이 핵심입니다. 다른 사람의 문제를 ‘어떻게’ 만들지 고민할 때 말이죠. 이걸 잘한다면 ‘어떻게’를 다른 곳에 넘겨버릴 수도 있습니다. 데이터베이스 엔진이 이걸 처리할 줄 알잖아. 혹은 로직 엔진이 이걸 검색할 줄 알지. 처럼요. 우리가 알 필요가 없어져요.

Who is about, like, data or entities. These are the things that our abstractions are going to be connected to eventually depending on how your technology works. You want to build components up from subcomponents in a sort of direct injection style. You don't want to, like, hardwire what the subcomponents are. You want to, as much as possible, take them as arguments because that's going to give you more programmatic flexibility in how you build things.
‘누구’란 데이터나 엔티티에 대한 것입니다. 추상화란 결국 프로그램이 작동하는 방식에 따라 데이터나 엔티티와 연결됩니다. 우리는 하위 컴포넌트들을 상위 컴포넌트에 주입하는 방식으로 만들고 싶잖아요. 하위 컴포넌트 코드를 상위 컴포넌트에 코드 형태로 넣고 싶진 않고요. 가능한 한 전달인자 형태로 가져오고 싶을 거예요. 그래야 프로그래밍이 유연해질 테니까요.
You should have probably many more subcomponents than you have, so you want really much smaller interfaces than you have, and you want to have more subcomponents than you probably are typically having because usually you have none. And then maybe you have one when you decide, oh, I need to farm out policy. If you go in saying this is a job, and I've done who, what, when, where, why, and I found five components, don't feel bad. That's great. You're winning massively by doing that. You know, split out policy and stuff like that.
하위 컴포넌트는 훨씬 더 많아져야 합니다. 그러려면 인터페이스는 더 작아져야 하고요. 아마 평소에는 하위 컴포넌트가 없다시피 했을테니까, 원래 하려고 했던 것 보다 더 많이 만드세요. 그러다보면 어떤 정책을 위임할 것인가, 로부터 하나의 컴포넌트가 생성될 것입니다. 누가, 무엇을, 언제, 어디서, 왜 다섯 가지에 대해서 다섯 가지 컴포넌트를 찾았다 말하는 것이 잘못되었다 느끼지 마세요. 이건 대단한 일이예요. 이렇게 하는 과정 자체에서 이미 많은 걸 얻은 거예요. 정책과 기능을 분리해내고 있잖아요.
And the thing that you have to be aware of when you're building, you know, the definition of a thing from subcomponents is any of those kind of, you know, yellow thinking about blue, blue thinking about yellow kind of hidden detail dependencies, so you want to avoid that.
이 하위 컴포넌트는 노란색이고, 파란색을 생각할 수 있어야 하지. 우리가 관심 쏟아야하는 부분은 이런 거죠. 숨겨져있던 세부적인 의존성들 말이예요. 그래야 상황을 대비할 수 있죠.

How things happen, this is the actual implementation code, the work of doing the job. You strictly want to connect these things together using those polymorphism constructs. That's the most powerful thing. Yeah, you can use a switch statement. You could use pattern matching. But it's glomming all this stuff together.
‘어떻게’는 실제로 구현하는 코드입니다. 프로그램이 수행하는 일이죠. 이제야말로 다형성 구조를 사용해서 이것들을 연결하면 될까요? 가장 강력한 도구니까요. 스위치 문을 쓰고, 패턴 매칭을 쓰고 말이죠. 하지만 이렇게 하는 순간 모든 것이 섞여 버리는 거예요.
If you use one of these systems, you have an open polymorphism policy, and that is really powerful, especially if it's runtime open. But even if it's not, it's better than nothing. And again, beware of abstractions that dictate how in some subtle way because, when you do that, you're really, you're nailing the person down the line who has to do the implementation. You're tying their hands. So the more declarative things are, the better, the better things work. And the thing that -- I mean, how is sort of the bottom, right? Don't mix this up with anything else. All these implementations should be islands as much as possible.
유연한 시스템을 사용하고 있다면 개방된 다형성 정책이 존재할 거예요. 특히 런타임 개방이라면 더욱 강력하죠. 하지만 유연하지 않은 시스템을 사용하더라도 괜찮아요. 시스템이 없는 것보다는 나으니까요. 추상 안에 행동 방침을 암시하는 경우만 주의하세요. 그렇게 하면 실제로 구현할 사람을 어딘가에 못박아버리는 셈이니까요. 손발을 묶어 꼼짝못하게 만드는 거예요. 그러니 좀더 선언적으로 작성하세요. 그게 더 나은 방법이고, 더 잘 작동합니다. 그리고 슬라이드의 마지막 항목은 어떤가요? 그 어떤 것도 ‘어떻게’와 섞지 마세요. 모든 구현 코드들은 가능한 한 그 자체로 외딴섬이어야 합니다.

When and where, this is pretty simple. I think you just have to strenuously avoid complecting this with anything. I see it accidentally coming in, mostly when people design systems with directly connected objects. So if you know your program is architected [such that this thing deals with the input and then this thing has to do the next part of the job.] Well, if thing A calls thing B, you just complected it. Right? And now you have a when and where thing because now A has to know where B is in order to call B, and when that happens is whenever A does it.
‘언제’와 ‘어디서’. 이건 간단합니다. 다른 것들과 엮이는 상황을 최대한 열심히 막으세요. 엮임은 의도치 않게 시작됩니다. 사람들은 시스템을 설계하면서 객체들을 서로 연결하죠. 여러분이 어떤 프로그램의 구조를 이해하고 있다고 해보죠. 입력이 들어오면 A가 처리하고, 그 다음 작업은 B에서 처리합니다. 만약 여기서 A가 B를 호출한다면, 여러분은 방금 둘을 엮은 거예요. ‘언제’와 ‘어디서’도 엮이기 시작했습니다. A가 B를 호출하려면 B가 어디 있는지 알아야 하니까요. 그리고 A가 ‘언제’ 호출했는지도 엮여 있죠.
Stick a queue in there. Queues are the way to just get rid of this problem. If you're not using queues extensively, you should be. You should start right away, like right after this talk.
이럴 땐 큐를 사용하세요. 이 문제를 해결하는 방법은 큐입니다. 큐를 많이 사용하지 않았다면, 이제부턴 사용하세요. 옳은 길을 택하세요. 이 강연 끝나자마자 바로요.
[Audience laughter]
[관객들의 웃음]

And then there's the why part. This is sort of the policy and rules. This is -- I think this is hard for us. We typically put this stuff all over our application. Now if you ever have to talk to a customer about what the application does, it's really difficult to sit with them in source code and look at it.
그 다음은 ‘왜’입니다. 규칙과 정책이 등장하죠. 우리가 어려워하는 부분이긴 해요. 애플리케이션 전체에 이것들이 존재하니까요. 혹시 고객과 대화해 본 적이 있나요? 애플리케이션이 무얼 해야하는지에 대해서요. 고객과 함께 소스코드를 들여다봤다면 굉장히 힘들었을 겁니다.
Now, if you have one of these pretend testing systems that lets you write English strings so the customer can look at that, that's just silly. You should have code that does the work that somebody can look at, which means to try to, you know, put this stuff someplace outside. Try to find a declarative system or a rule system that lets you do this work.
영어 글자를 쓸 수 있는 모의 시험 시스템 같으니까, 어리석어보였을 거예요. 코드는 사람들이 눈으로 볼 수 있는 작업을 해야 해요. 그러니까 규칙과 정책을 바깥 어딘가에 두라는 말입니다. 선언형 시스템이나 규칙 시스템 같은 걸 검토하고 적용해보세요.

Finally, in this area, information: it is simple. The only thing you can possibly do with information is ruin it.
마지막입니다. 이 분야에서는 정보야말로 단순합니다. 우리가 정보를 갖고 할 수 있는 유일한 일은 정보를 망치는 것입니다.
[Audience laughter]
[관객들의 웃음]
Don't do it! Right? Don't do this stuff. I mean, we've got objects. Objects were made to, like, encapsulate IO devices, so there's a screen, but I can't, like, touch the screen, so I have the object. Right? There's a mouse. I can't touch the mouse, so there's an object. Right? That's all they're good for. They were never supposed to be applied to information. And we apply them to information that's just wrong.
그러지 마세요. 슬라이드에 적힌 이런 것들을 하시면 안 됩니다. 객체 있죠? 객체는 입출력 장치를 캡슐화하죠. 화면도 캡슐화 해요. 제가 화면을 직접 건드리진 못하죠. 마우스도 있어요. 마우스도 제가 직접 제어하진 못하죠. 이럴 때 쓰려고 객체가 있는 거예요. 이런 데에선 객체가 바른 역할을 합니다. 하지만 정보에 적용하라고 존재한 적은 없어요. 정보를 객체에 적용했다면 그건 명확한 잘못입니다.
It's wrong. But I can now say it's wrong for a reason. It's wrong because it's complex. In particular, it ruins your ability to build generic data manipulation things. If you leave data alone, you can build things once that manipulate data, and you can reuse them all over the place, and you know they're right once and you're done.
잘못이예요. 잘못됐다고 말할 근거도 있어요. 그건 복잡하기 때문에 잘못입니다. 제네릭 데이터를 조작하는 능력을 망쳐버리기 때문에 잘못입니다. 데이터를 그대로 두면, 한 번의 조작만으로 뭔가를 만들 수 있어요. 또, 여기저기서 재사용할 수도 있고요. 일단 그렇게 되면 우리 일은 끝난 거예요.
The other thing about it, which also applies to ORM is that it will tie your logic to representational things, which again tying, complecting, intertwining. So represent data is data. Please start using maps and sets directly. Don't feel like I have to write a class now because I have a new piece of information. That's just silly.
다른 데에도 적용할 수 있는데요. ORM입니다. ORM은 로직과 표현 데이터를 서로 묶죠. 묶고, 엮고, 섞어 버려요. 표현 데이터도 데이터입니다. 그냥 맵과 세트를 쓰세요. 새 정보를 나타낼 새 클래스를 작성해야지. 라고 하지 마세요. 어리석은 일입니다.


So the final aspect, right, so we choose simple tools. We write simple stuff. And then sometimes we have to simplify other people's stuff. In particular, we may have to simplify the problem space or some code that somebody else wrote. This is a whole separate talk I'm not going to get into right now. But the job is essentially one of disentangling, right? We know what's complex. It's entangled. So what do we need to do? We need to somehow disentangle it.
그래서 마지막 측면은, 우리는 단순한 도구를 선택합니다. 단순한 결과물을 만들죠. 가끔은 다른 사람이 만든 것들도 단순화하고요. 다른 사람이 작성한 코드나 문제 영역(problem space)를 단순화해야하는 상황 말이예요. 이런 상황은 오늘 주제를 벗어난 이야기라 지금은 다루지 않겠습니다. 우리 업무란 결국 얽힌 걸 푸는 겁니다. 복잡함이 뭔지 아니까요. 그건 얽힌 거죠. 그럼 우린 뭘 하죠? 어떻게든 풀어내죠.
You're going to get this. You're going to need to first sort of figure out where it's going. You're going to have to follow stuff around and eventually label everything. This is the start. This is roughly what the process is like. But again, it's a whole separate talk to try to talk about simplification.
우린 이런 얽힌 것들을 발견할 겁니다. 그럼 그게 어떻게 작동하는지 알아내야겠죠. 졸졸 따라다니면서 모든 것에 레이블을 붙일 테고요. 그렇게 시작할 겁니다. 처리 과정이 대충 그렇다는 겁니다. 그렇지만 어쨌든 무언가를 단순화하는 건 또다른 이야기입니다.

All right, I'm going to wrap up a couple of slides. The bottom line is simplicity is a choice. It's your fault if you don't have a simple system. And I think we have a culture of complexity. To the extent we all continue to use these tools that have complex outputs, we're just in a rut. We're just self-reinforcing. And we have to get out of that rut. But again, like I said, if you're already saying, "I know this. I believe you. I already use something better. I've already used that whole right column," then hopefully this talk will give you the basis for talking with somebody else who doesn't believe you.
자 이제 슬라이드 몇 장으로 정리해보겠습니다. 단순함은 여러분의 선택에 달려 있습니다. 여러분의 시스템이 단순하지 않다면, 그건 여러분 잘못입니다. 우리가 복잡함이라는 문화에 살고 있죠. 그렇다고, 복잡한 결과물을 만드는 도구를 계속 사용하는 한 복잡함을 벗어나지 못할 겁니다. 확증 편향하게 되는 거죠. 이 굴레에서 벗어나야 합니다. 누군가는 이렇게 말할지도 모르겠어요. “저도 알아요. 당신 말을 믿습니다. 저도 그런 걸 이미 하고 있어요. 저는 단순함 칸에 있는 걸 다 써봤어요.” 그렇다면 바라건데, 여러분이 누군가를 설득해야 할 때 이 강연 내용이 근거가 되면 좋겠습니다.
Talk about simplicity versus complexity. But it is a choice. It requires constant vigilance. We already saw that guardrails don't yield simplicity. They don't really help us here.
복잡성과 단순함이 대결하는 논의에서 말이죠. 하지만 그건 선택의 문제입니다. 계속해서 경계해야 하죠. 가드레일이 단순함을 유발하지는 않음을 이미 살펴봤죠. 정말로 별로 도움이 되지 않습니다.
It requires sensibilities and care. Your sensibilities about simplicity being equal to ease of use are wrong. They're just simply wrong. Right? We saw the definitions of simple and easy. They're completely different things. Easy is not simple.
단순함은 감성과 보살핌을 요합니다. 단순함을 사용 편의성으로 여기려는 여러분의 감성은 틀렸습니다. 단순하게도 틀렸어요. 단순함의 정의와 쉬움의 정의를 살펴봤으니까요. 이 둘은 완전히 다른 것이었죠. 쉬움이 단순함은 아닙니다.
You have to start developing sensibilities around entanglement. That's what you have to -- you have to have entanglement radar. You want to look at some software and say, uh! You know, not that I don't like the names you used or the shape of the code or there was a semicolon. That's also important too. But you want to start seeing complecting. You want to start seeing interconnections between things that could be independent. That's where you're going to get the most power.
얽힌 것들에 대한 감성을 키우기 바랍니다. 얽힘을 감지하는 레이더 같은 걸 가져야 해요. 어떤 소프트웨어를 봤을 때, 이름이나 코드 모양, 세미콜론이 마음에 안든다고 말하지 마세요. 물론 중요합니다만, 엮임부터 찾아가길 바랍니다. 요소들이 서로 연결되는 부분을 찾고, 독립시킬 수 있을지를 살펴보세요. 이런 감성이 여러분이 가진 가장 강력한 힘이 될 겁니다.
All the reliability tools you have, right, since they're not about simplicity, they're all secondary. They just do not touch the core of this problem. They're safety nets, but they're nothing more than that.
모든 신뢰성 도구는 단순함에 대한 도구가 아닙니다. 따라서 보조 도구일 뿐입니다. 이 도구들은 문제의 본질을 건드리지 않습니다. 안전망이긴 하지만 그 이상은 아닙니다.

So, how do we make simplicity easy? Right? We're going to choose constructs with simpler artifacts and avoid constructs that have complex artifacts. It's the artifacts. It's not the authoring. As soon as you get in an argument with somebody about, oh, we should be using whatever, get that sorted out because, however they feel about the shape of the code they type in is independent from this and this is the thing you have to live with.
그럼 어떻게 해야 단순함을 수월하게 만들 수 있을까요? 단순한 결과물을 만드는 도구를 선택하고, 복잡한 결과물을 만드는 도구는 사용하지 마세요. 저작 도구가 아닌 결과물이 중요합니다. 누군가가 “우린 이 도구를 사용해야만 해”라고 말한다면 그 사람과 이야기부터 하세요. 그들이 코드 모양에서 느끼는 감정과 이 도구는 서로 독립적이라고, 단순함을 우선해야 한다고요.
We're going to try to create abstractions that have simplicity as a basis. We're going to spend a little time upfront simplifying things before we get started. And recognize that when you simplify things, you often end up with more things. Simplicity is not about counting. I'd rather have more things hanging nice, straight down, not twisted together, than just a couple of things tied in a knot. And the beautiful thing about making them separate is you'll have a lot more ability to change it, which is where I think the benefits lie. So I think this is a big deal, and I hope everybody is able to bring it into practice or use this as a tool for convincing somebody else to do that.
단순함이라는 기초 위에 추상을 생성하려고 노력합시다. 가끔은 이미 존재하는 걸 단순화하는 데 시간을 들여야 할 겁니다. 그걸 단순화하다보면 더 많은 걸 얻게 된다는 점도 깨달을 겁니다. 단순함은 숫자가 적다는 뜻이 아닙니다. 몇 개 안 되는 줄이 서로 엮여 있기보다는, 많은 줄이 곧게 뻗어 있는 편이 낫습니다. 이런 식으로 요소들을 분리하다보면 그걸 변화시킬 능력을 더 많이 얻게 됩니다. 이 작업의 장점이죠. 그러니까 정말 중요한 건, 모든 분이 이 강연 내용을 연습해보고, 다른 사람을 설득하는 도구로 사용하길 바랍니다.

So I'll leave you with this. This is what you say when somebody tries to sell you a sophisticated type system.
그럼 이만 마치겠습니다. 이 말은 정교한 타입 시스템을 홍보하려는 사람을 만났을 때 써먹어보세요.
[Audience laughter]
[관객들의 웃음]
Thank you.
감사합니다.
[Audience applause]
[관객들의 박수]

